Datastax Cassandra Driver本身是启用了metrics且启用了jmx report功能,即提供了丰富的性能监控功能。
可以通过com.datastax.driver.core.Cluster.Builder看出来:
private boolean metricsEnabled = true; private boolean jmxEnabled = true; metricsEnabled ? new MetricsOptions(jmxEnabled) : null
我们可以查阅代码看都report了哪些信息:
private final Timer requests = registry.timer("requests");
private final Gauge<Integer> knownHosts = registry.register("known-hosts", new Gauge<Integer>()
private final Gauge<Integer> connectedTo = registry.register("connected-to", new Gauge<Integer>()
private final Gauge<Integer> openConnections = registry.register("open-connections", new Gauge<Integer>()
当然也可以使用visualvm/jconsole等工具直接查看mbean。
ps: 如果远程查看的话,记得加上 -Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false ,其中端口号要大于1024:
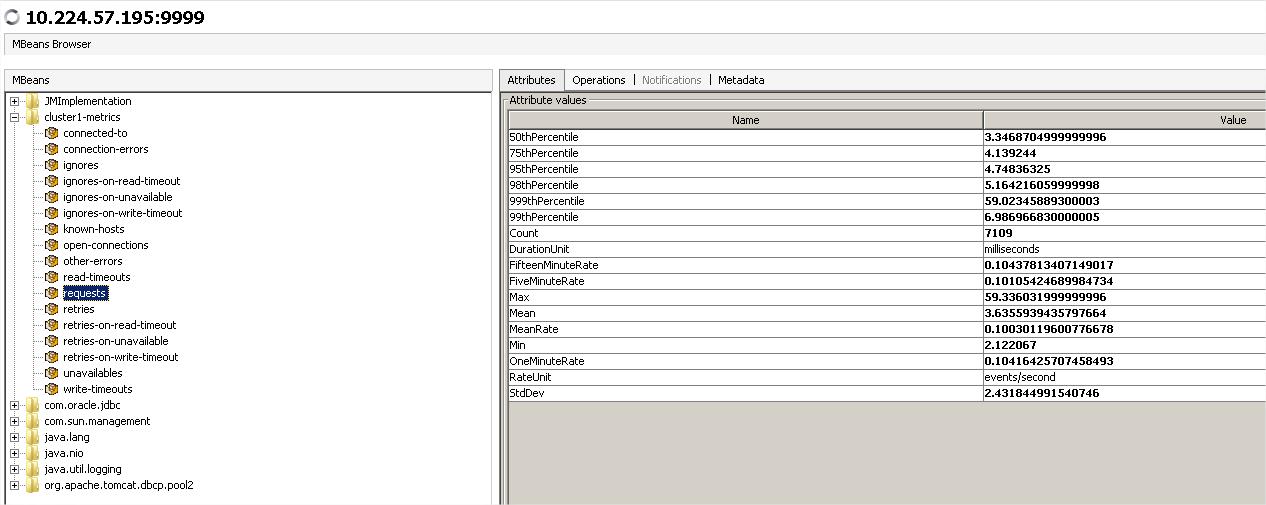
基本上字面意思解释的很清楚,比较难理解的是以下几点:
(1)StdDev:标准差,标明数据样本与平均数之间的差异的情况,越大代表样本分散越不均匀
(2)DurationUnit是处理Event的时间消费的单位,即50thpercentile(ile即<=)等的单位
(3)999thpercentile=99.9thpercentile
(4)最近1/5/15分钟的速率不是真实的存这么长时间然后算平均数,而是按照一定的算法(linux中的top)来计算的。
(5)median: 中数,所有数据样本中,最中间的数,即50%的概念以此为界限。
Metric本身很有用,例如可以通过它可以查看建立了多少连接,接受到多少请求,请求失败率,请求的处理的平均时间/最大时间/最小时间等,完成一定的性能监控。
而性能指标中“处理请求消费的时间”是什么时间段,可以查阅代码:
从:
public RequestHandler(SessionManager manager, Callback callback, Statement statement) {
......
this.timerContext = metricsEnabled()
? metrics().getRequestsTimer().time()
: null;
this.startTime = System.nanoTime();
}
到:
com.datastax.driver.core.RequestHandler.setFinalResult(Connection, Response) or com.datastax.driver.core.RequestHandler.setFinalException(Connection, Exception)
基本上可以认为就是一个请求从建立到接受之后的时间消费,这样我们可以定期去用visual vm或者jconsole等查看下。
写到这里我们可知,对于cassandra driver本身,实际上是有性能监控的方法(不过metrics官网提及对于高吞吐量、低延时的项目使用metric效果并不好,同时也提及jmx这种方式不适合产品级监控)。
而如果我们不知道它的存在,也没有利用上会有什么坏处? 不言而喻,会浪费driver代码的处理时间和CPU占用时间。
通过之前的一些测试,Driver本身处理的TPS能力对CPU的配置非常敏感,以所做的项目为例,2核时可以达到600TPS,但是在8核下可以达到3000TPS.所以我们可以通过Jprofiler来看看默认的Metric性能监控对CPU的影响:

可以看出,Metrics的性能监控占用了14.2%的CPU时间。
所以从另外一个角度说,如果去掉Metrics监控可以节约CPU资源从而提高TPS.
Cluster.builder().withoutMetrics()
如果不仔细阅读代码,可能会使用Cluster.builder().withoutJMXReporting().
一定要区分:前者是关闭Metrix,也同时不会启动JMX来report;而后者仅仅是关闭了JMX report但是仍然会监控性能。
总结:通过Metrics Options配置,我们可以使用它来监控Driver的性能,如果我们不想用或者不方便用或压根不知道这个功能,那么阅读本文之后,就直接禁用吧,这样会节约一些CPU资源,提升一定的性能。
这里需要提及的是,对于Metrics本身,除了JMX展示,还可以使用console/http/csv/SLF4J 等来展示。
当然datastax的driver使用的是metric+jmx这种方式。
driver中JMX reporter是可以替换成其他类型的,例如console, slf4j, cvs等定时输出的方式,置换方式只要几行代码,例如换成每1分钟输出监控数据一次:
cluster = Cluster.builder()
.addContactPoints(nodes.split(",")).withoutJMXReporting() //close jmx report
.build();
MetricRegistry registry = cluster.getMetrics().getRegistry();
Slf4jReporter.forRegistry(registry).build().start(1, TimeUnit.MINUTES); //swich to log4j
03-19 2015 02:14:18:361 [metrics-logger-reporter-thread-1] INFO metrics – type=GAUGE, name=connected-to, value=3
03-19 2015 02:14:18:362 [metrics-logger-reporter-thread-1] INFO metrics – type=GAUGE, name=known-hosts, value=11
03-19 2015 02:14:18:362 [metrics-logger-reporter-thread-1] INFO metrics – type=GAUGE, name=open-connections, value=4
03-19 2015 02:14:18:362 [metrics-logger-reporter-thread-1] INFO metrics – type=COUNTER, name=connection-errors, count=0
03-19 2015 02:14:18:362 [metrics-logger-reporter-thread-1] INFO metrics – type=COUNTER, name=ignores, count=0
03-19 2015 02:14:18:362 [metrics-logger-reporter-thread-1] INFO metrics – type=COUNTER, name=ignores-on-read-timeout, count=0
03-19 2015 02:14:18:362 [metrics-logger-reporter-thread-1] INFO metrics – type=COUNTER, name=ignores-on-unavailable, count=0
03-19 2015 02:14:18:363 [metrics-logger-reporter-thread-1] INFO metrics – type=COUNTER, name=ignores-on-write-timeout, count=0
03-19 2015 02:14:18:363 [metrics-logger-reporter-thread-1] INFO metrics – type=COUNTER, name=other-errors, count=0
03-19 2015 02:14:18:363 [metrics-logger-reporter-thread-1] INFO metrics – type=COUNTER, name=read-timeouts, count=0
03-19 2015 02:14:18:363 [metrics-logger-reporter-thread-1] INFO metrics – type=COUNTER, name=retries, count=0
03-19 2015 02:14:18:363 [metrics-logger-reporter-thread-1] INFO metrics – type=COUNTER, name=retries-on-read-timeout, count=0
03-19 2015 02:14:18:363 [metrics-logger-reporter-thread-1] INFO metrics – type=COUNTER, name=retries-on-unavailable, count=0
03-19 2015 02:14:18:364 [metrics-logger-reporter-thread-1] INFO metrics – type=COUNTER, name=retries-on-write-timeout, count=0
03-19 2015 02:14:18:364 [metrics-logger-reporter-thread-1] INFO metrics – type=COUNTER, name=unavailables, count=0
03-19 2015 02:14:18:364 [metrics-logger-reporter-thread-1] INFO metrics – type=COUNTER, name=write-timeouts, count=0
03-19 2015 02:14:18:365 [metrics-logger-reporter-thread-1] INFO metrics – type=TIMER, name=requests, count=30, min=2.6754119999999997, max=8.28019, mean=3.9076371, stddev=1.0645403774100675, median=3.8236345, p75=4.342703, p95=6.798477349999997, p98=8.28019, p99=8.28019, p999=8.28019, mean_rate=0.12499429465364886, m1=0.10222425153981142, m5=0.06690157349035725, m15=0.02901789392361707, rate_unit=events/second, duration_unit=milliseconds
学习要点:Metrics

