在持续集成领域,一个产品的发布往往都有自己的过程周期(lifecycle),大体都会划分为:构建->部署->测试->发布等几个重要阶段,其中测试是发布产品前不可或缺的重要阶段,是产品质量的保证。而能让持续集成奏效,除了要求测试脚本更充分健壮,还要求测试脚本运行得更快更好。这点对于小型项目而言可能显得无关紧要,毕竟大多小项目的测试脚本不过百条,验证点不过千“点”;但对于一个大型项目而言,测试代码源文件可能成百上千,执行完所有的测试可能要等很久,而苦等之后的结果却可能是满眼的failure, 于是如果提高测试执行速度成为迫切需要解决的问题,试想把测试阶段从2小时压缩到1小时,再从1小时压缩到30分钟,每次时间压缩带来的不仅是技术人员本身的成就感,更是对整个产品发布过程体验的改善。
那么如何加速测试的执行呢?提起速度,我们立马可能联想到“性能”调优的步骤:先进行tuning,然后找到问题的瓶颈所在,最后逐个击破。本文暂不讨论如何进行这些步骤, 而是基于C++和Java为语言案例,TestNG和Google test为测试框架,Jenkins为持续平台做分析,从以下六个层次提出提高测试执行的一般方法:
硬件资源层次
工欲善其事必先利其器,提高硬件(CPU、内存、磁盘等)配置是改善执行速度的“硬”方法,硬件资源的优化不应仅仅局限在单机自身的各项指标提升,在需求不断提高的情况下,可以考虑实施虚拟机、分布式集群等方式来进一步获取更优的硬件资源,当然,涉及分布式执行时,可以借助以下持续集成平台层次的“软”实施来共同作用。
另外,在硬件资源紧张的情况下,不同项目或者不同团队可能不得不复用一套测试环境,造成可利用资源更为紧张,此时可以错开时间测试(例如A项目组测试定时在凌晨0点启动,B项目组定时在凌晨2点)以提高速度。
语言编码实现层次
测试代码本身也是代码,显而易见,如果代码编写时注重效率,速度上肯定有所收益。这点可能需要“纠结”于一些日常的编码细节:例如Java中Stringbuffer和Stringbuilder的比较;C++中是i++和++i的比较。这种语言层次提高效率的文章书籍很多,这里不做过多描述。在语言编码层次上最重要的不是这些语言细节,而是避免一些消费时间的测试代码设计,减少不必要的耗时操作,例如以下几点:
(1) 冗余的日志信息,不合理的日志级别设置等
输出日志带来的磁盘频繁访问必然让速度下降,所以在保证日志信息充足的前提下,尽量减少日志,或者只记录失败测试的日志(毕竟对于测试者而言很少去关注成功日志),可以让测试加快。
(2) 不合理的等待
用户执行完某个操作,必须等待某条件的发生(例如DB里面插入一条新数据)进而执行后续动作是测试中经常面对的场景,那么等待多久成为需要考虑的问题,假设用TimeUnit.MINUTES.sleep(1)等待一分钟,在10秒即可满足条件的场景下浪费的就是50秒,所以这里必须去考虑合理sleep的时间来兼顾对资源的消耗和运行速度的影响,同时在等待方式上也可以考虑是采用循环短时间条件等待或异步通知的方式去进行。
(3) 用例的过程
先执行完所有测试步骤,然后做对所有步骤做一次性校验,还是做完一步校验一步,这两种方式的速度在不同场景下有所不同,所以需要权衡;相类似的,对于需要获取DB连接的用例,是每条都执行获取DB连接然后释放连接,还是所有用例执行之前获取连接,所有case执行完之后释放连接也会对执行速度有所影响。
构建测试脚本层次
对于一个大型项目,源文件的数目庞大或依赖的dependency过多导致代码编译占用大量时间,如何提高编译代码的速度?除了使用更好的磁盘,注重代码编写时对编译速度的影响,还可以针对不同的语言采取不同的有效策略,例如针对C++, 使用make命令编译项目时,可以加上参数-j来并行编译项目。-j参数的含义可以参考下文:
-j [jobs], –jobs[=jobs]
指定同步运行的作业(命令)的数量。如果有一个以上-j选项,那么只有最后一个有效。如果-j选项没有参数,那么编译过程就不会限制能够同步运行的作业的数量。
需要说明的是,编译过程可能要求特定的顺序而导致并行编译失败,如果遇到这种问题,可以先并行、后串行(去掉-j)重复执行一次以解决。
而对于java,Maven 3 开始支持并发build,提供了以下几种常见方式:
- mvn -T 4 clean install # Builds with 4 threads
- mvn -T 1C clean install # 1 thread per cpu core
- mvn -T 1.5C clean install # 1.5 thread per cpu core
同时使用maven管理java项目常出现时间消耗在依赖jar的下载上,此时可以检查是否有冗余失效的repository配置、较长的下载timeout时间设置、所选择repository的连接速度等,甚至在不同测试环境下可以使用 profile来管理repository来加速测试脚本构建。
测试框架支持层次
在测试框架支持层次上,应该充分运用框架本身提高的丰富功能来提高测试执行速度,以Java测试框架TestNG为例:
(1) 利用timeout控制失效等待
如果某个测试用例等待某条件的触发而陷入长时间等待,等待的时间过长往往对于用例本身而言已失效,特别是当条件永远无法满足时。因此需要控制用例执行允许的最大timeout时间。TestNG可以给test或者test suite设置 timeout时间,分别控制具体某个或一组(testing.xml配置)自动化测试用例执行的最大允许时间:
- @Test(timeout = 1000)
- testng.xml : <suite name=”Module Test” parallel=”none” time-out=”200000″>
(2) 利用@BeforeTest、@BeforeClass等条件注解,减少无意义测试
测试的顺利完成都需要满足很多基础条件,例如需要测试环境就绪, 如果不使用@before类标签,则当条件不具备时,仍然会执行完所有的用例,必然带来巨大的时间浪费,因此使用@before类标签可以避免无意义的测试,@before标记的方法一旦失败,后续的相应的测试不会继续进行。
(3) 使用框架自带的多线程支持
例如对于TestNG自身,可以在testng.xml中设置parallel参数来指定是否并发以及并发的级别:methods|tests|classes,除了测试框架自身外,软件项目管理工具也可以提供多线程支持,例如maven的测试组件maven-surefire-plugin,提供了并发参数的设置:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.16</version>
<configuration>
<parallel>methods</parallel>
<threadCount>10</threadCount>
</configuration>
</plugin>
持续集成平台层次
现在市场上存在不少持续集成平台,大多持续集成平台支持并发执行用例然后汇总、发布测试结果,从而最大化提高测试执行速度。而并发执行的前提是测试代码本身及测试代码的组织支持并发,如果测试本来就含有多个模块,那么直接并发运行多个模块,最后汇总结果即可。如java以testng.xml为模块,gtest以makefile为模块,所以相比较顺序执行4个模块,并发使用4个Job并发执行,那么时间压缩可以达到4倍。在实际应用中,即使在同一个模块,我们仍然面对自动化测试用例数目过多运行速度过慢的问题,此时,可以考虑将单一模块拆分成子模块,对于Java而言较简单,配置下测试套件的xml即可;而对C++而言,如果不允许直接复制粘贴原有的makefile,就需要重新设计makefile以复用, 例如将makefile中编译的test cases定义分拆到多个makefile(如下图测试模块1的makefile引用了共用的makefile并添加了自己的测试用例)中,然后并发执行多个makefile。
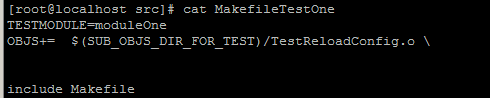
为并发执行多个job, 持续集成平台必须提供必备的支持,以Jenkins为例,可以使用multijob插件来实施,配置多个测试模块同时进行.
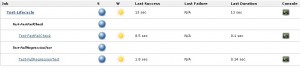
并发完测试后,讲所有测试结果汇总到一个地方,然后使用xunit plugin来汇总结果(如下图),它可以汇总多个文件,且支持cpptest、gtest等输出结果格式。

过程改进层次
在产品的持续集成生命周期中,可以将测试拆分成两部分放在两个阶段:基本功能快速校验阶段(fast fail)和基本功能之外的全面测试阶段。如果产品在第一阶段最基本的功能都无法通过,那么部署之后进行全面测试纯属浪费时间,这个阶段的引入可以快速的校验产品是否有必要开展全面测试。这点类似与测试用例中添加了@before类标签所带来的收效,不过更宏观且阶段划分的更清晰。
原有过程:构建阶段->部署阶段->测试阶段->发布阶段
细化后过程:构建阶段->部署阶段->基本功能快速校验阶段->全面测试阶段—>发布阶段
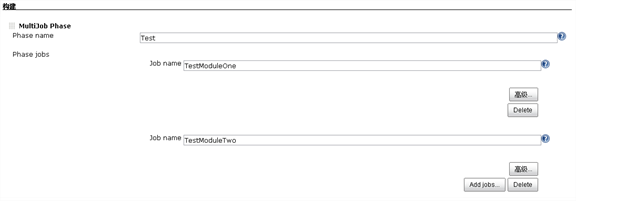
这种过程优化可以利用持续集成平台来支持,例如对于Jenkins系统,可以使用multijob插件,将基本功能快速校验和全面测试阶段分列在不同的phase即可,执行效果如下:
结论
通过上面由微观到宏观六个不同层次的分析可知,要加速测试用例的执行是一个系统的过程,单靠某一方面分析可能有所偏失,并不能将测试用例的执行速度发挥极致。同时,本文针对不同层次的分析也没有提供step by step的方式描述每一个细节,只是点到为止,所以读者可以根据自己采用的语言、测试框架、持续集成平台做类似更有针对性的分析,相信在综合不同层次的综合调优后,可以让持续集成实施的更快、更好。
