redis有很多monitor工具,但是基本原理都是使用info命令来获取信息然后来展示:
127.0.0.1:7001> info all # Server redis_version:3.2.8 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:7599ffb66fcadaf8 redis_mode:cluster os:Linux 2.6.32-696.6.3.el6.x86_64 x86_64 arch_bits:64 multiplexing_api:epoll gcc_version:4.4.7 process_id:21982 run_id:b82d40a090a5b146d9f061259f2e6ecfbfa1a5e0 tcp_port:7001 uptime_in_seconds:63911 uptime_in_days:0 hz:10 lru_clock:12110104 executable:/opt/redis/bin/redis-server config_file:/etc/redis/wbx-redis.conf # Clients connected_clients:2 client_longest_output_list:0 client_biggest_input_buf:0 blocked_clients:0 # Memory used_memory:98917520 used_memory_human:94.34M used_memory_rss:108572672 used_memory_rss_human:103.54M used_memory_peak:98961112 used_memory_peak_human:94.38M total_system_memory:4018577408 total_system_memory_human:3.74G used_memory_lua:37888 used_memory_lua_human:37.00K maxmemory:100000000 maxmemory_human:95.37M maxmemory_policy:allkeys-lru mem_fragmentation_ratio:1.10 mem_allocator:jemalloc-4.0.3 # Persistence loading:0 rdb_changes_since_last_save:532485 rdb_bgsave_in_progress:0 rdb_last_save_time:1505218417 rdb_last_bgsave_status:ok rdb_last_bgsave_time_sec:-1 rdb_current_bgsave_time_sec:-1 aof_enabled:0 aof_rewrite_in_progress:0 aof_rewrite_scheduled:0 aof_last_rewrite_time_sec:-1 aof_current_rewrite_time_sec:-1 aof_last_bgrewrite_status:ok aof_last_write_status:ok # Stats total_connections_received:1074 total_commands_processed:543078 instantaneous_ops_per_sec:45 total_net_input_bytes:62456064 total_net_output_bytes:11663285 instantaneous_input_kbps:4.54 instantaneous_output_kbps:0.04 rejected_connections:0 sync_full:0 sync_partial_ok:0 sync_partial_err:0 expired_keys:0 evicted_keys:0 keyspace_hits:0 keyspace_misses:0 pubsub_channels:0 pubsub_patterns:0 latest_fork_usec:0 migrate_cached_sockets:0 # Replication role:slave master_host:10.224.2.144 master_port:7001 master_link_status:up master_last_io_seconds_ago:1 master_sync_in_progress:0 slave_repl_offset:62398387 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 # CPU used_cpu_sys:140.97 used_cpu_user:95.84 used_cpu_sys_children:0.00 used_cpu_user_children:0.00 # Commandstats cmdstat_set:calls=439235,usec=8234980,usec_per_call=18.75 cmdstat_del:calls=93249,usec=1159357,usec_per_call=12.43 cmdstat_select:calls=1,usec=4,usec_per_call=4.00 cmdstat_auth:calls=1077,usec=7197,usec_per_call=6.68 cmdstat_ping:calls=6295,usec=16085,usec_per_call=2.56 cmdstat_flushall:calls=1,usec=14,usec_per_call=14.00 cmdstat_info:calls=2134,usec=171722,usec_per_call=80.47 cmdstat_cluster:calls=1085,usec=113780,usec_per_call=104.87 cmdstat_command:calls=1,usec=1016,usec_per_call=1016.00 # Cluster cluster_enabled:1 # Keyspace db0:keys=345986,expires=0,avg_ttl=0
另外对于cluster的信息,可以使用cluster info命令来展示:
127.0.0.1:7001> cluster info cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:6 cluster_my_epoch:4 cluster_stats_messages_sent:276455 cluster_stats_messages_received:276455
这里使用collectd来收集信息,具体而言是使用collectd redis plugin来收集数据:
https://github.com/powdahound/redis-collectd-plugin
当前不支持显示更多的cluster信息,已create PR去支持.
具体配置可以配置多个:
<LoadPlugin python>
Globals true
</LoadPlugin>
<Plugin python>
ModulePath "/opt/collectd/lib64/collectd"
Import "redis_info"
<Module redis_info>
Host "localhost"
Port {{port}}
Auth "{{password}}"
Verbose false
Instance "redis"
# Redis metrics to collect (prefix with Redis_)
Redis_uptime_in_seconds "gauge"
Redis_uptime_in_days "gauge"
Redis_lru_clock "counter"
Redis_connected_clients "gauge"
Redis_connected_slaves "gauge"
Redis_blocked_clients "gauge"
Redis_rejected_connections "gauge"
Redis_evicted_keys "gauge"
Redis_expired_keys "gauge"
Redis_used_memory "bytes"
Redis_used_memory_peak "bytes"
Redis_maxmemory "bytes"
Redis_changes_since_last_save "gauge"
Redis_instantaneous_ops_per_sec "gauge"
Redis_rdb_bgsave_in_progress "gauge"
Redis_total_connections_received "counter"
Redis_total_commands_processed "counter"
Redis_master_repl_offset "gauge"
Redis_total_net_input_bytes "bytes"
Redis_total_net_output_bytes "bytes"
Redis_mem_fragmentation_ratio "gauge"
Redis_keyspace_hits "derive"
Redis_keyspace_misses "derive"
Redis_cluster_slots_assigned "gauge"
Redis_cluster_slots_ok "gauge"
Redis_cluster_slots_pfail:"gauge"
Redis_cluster_slots_fail:"counter"
Redis_cluster_known_nodes:"gauge"
Redis_cluster_size "gauge"
Redis_cluster_current_epoch "gauge"
Redis_cluster_my_epoch "gauge"
Redis_cluster_known_nodes "gauge"
Redis_cluster_stats_messages_sent "counter"
Redis_cluster_stats_messages_received "counter"
Redis_used_cpu_sys "gauge"
Redis_used_cpu_user "gauge"
Redis_used_cpu_sys_children "gauge"
Redis_used_cpu_user_children "gauge"
Redis_cmdstat_command_calls "counter"
Redis_cmdstat_command_usec "counter"
Redis_cmdstat_command_usec_per_call "gauge"
Redis_cmdstat_del_calls "counter"
Redis_cmdstat_del_usec "counter"
Redis_cmdstat_del_usec_per_call "gauge"
Redis_cmdstat_get_calls "counter"
Redis_cmdstat_get_usec "counter"
Redis_cmdstat_get_usec_per_call "gauge"
Redis_cmdstat_incr_calls "counter"
Redis_cmdstat_incr_usec "counter"
Redis_cmdstat_incr_usec_per_call "gauge"
Redis_cmdstat_info_calls "counter"
Redis_cmdstat_info_usec "counter"
Redis_cmdstat_info_usec_per_call "gauge"
Redis_cmdstat_lpop_calls "counter"
Redis_cmdstat_lpop_usec "counter"
Redis_cmdstat_lpop_usec_per_call "gauge"
Redis_cmdstat_lpush_calls "counter"
Redis_cmdstat_lpush_usec "counter"
Redis_cmdstat_lpush_usec_per_call "gauge"
Redis_cmdstat_lrange_calls "counter"
Redis_cmdstat_lrange_usec "counter"
Redis_cmdstat_lrange_usec_per_call "gauge"
Redis_cmdstat_monitor_calls "counter"
Redis_cmdstat_monitor_usec "counter"
Redis_cmdstat_monitor_usec_per_call "gauge"
Redis_cmdstat_mset_calls "counter"
Redis_cmdstat_mset_usec "counter"
Redis_cmdstat_mset_usec_per_call "gauge"
Redis_cmdstat_ping_calls "counter"
Redis_cmdstat_ping_usec "counter"
Redis_cmdstat_ping_usec_per_call "gauge"
Redis_cmdstat_sadd_calls "counter"
Redis_cmdstat_sadd_usec "counter"
Redis_cmdstat_sadd_usec_per_call "gauge"
Redis_cmdstat_select_calls "counter"
Redis_cmdstat_select_usec "counter"
Redis_cmdstat_select_usec_per_call "gauge"
Redis_cmdstat_set_calls "counter"
Redis_cmdstat_set_usec "counter"
Redis_cmdstat_set_usec_per_call "gauge"
Redis_cmdstat_setex_calls "counter"
Redis_cmdstat_setex_usec "counter"
Redis_cmdstat_setex_usec_per_call "gauge"
Redis_cmdstat_spop_calls "counter"
Redis_cmdstat_spop_usec "counter"
Redis_cmdstat_spop_usec_per_call "gauge"
Redis_cmdstat_srem_calls "counter"
Redis_cmdstat_srem_usec "counter"
Redis_cmdstat_srem_usec_per_call "gauge"
</Module>
</Plugin>
效果图(以circonus为例,当然也可以使用其他的展示平台):
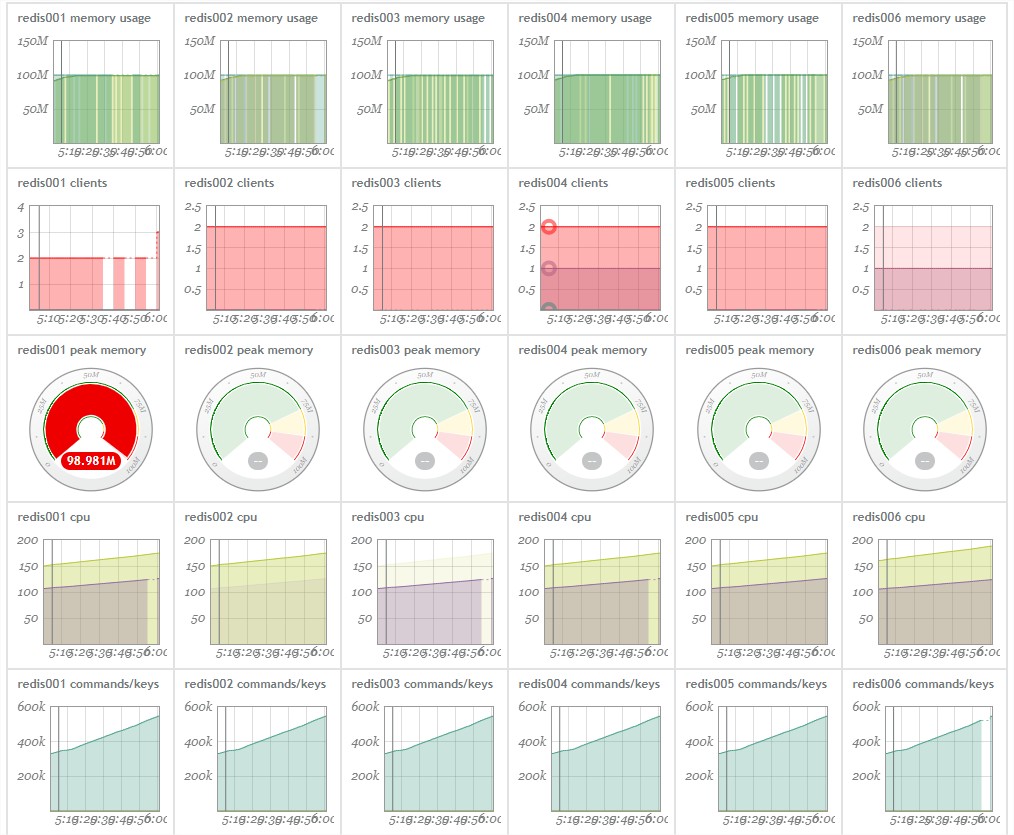
之后继续可以创建alert来报警。
例如监控redis是否继续活着,可以使用uptime_in_seconds多久没有数据,就触发报警,但是这种情况,考虑假设collectd有问题或者展示平台的收集模块有问题,会导致误报,所以这里不防尝试,主动报错的方式。
比如service不服务直接报告一个状态错误,这样如果有这个状态,且错误,一定就是错误,这样就可以避免误报:
例如修改python redis plugin:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((conf['host'], conf['port']))
log_verbose('Connected to Redis at %s:%s' % (conf['host'], conf['port']))
except socket.error, e:
collectd.error('redis_info plugin: Error connecting to %s:%d - %r'
% (conf['host'], conf['port'], e))
return {"alive" : "0"} //原来是return None
最终效果:
ALERT Severity 1 Check: rediscluster / redis001 Host: 10.224.2.141 Metric: redis_info`redis`gauge`alive (0.0) Occurred: Wed, 13 Sep 2017 16:24:30 redis server is down, please check......
但是这种情况仍然需要考虑一种情况,假设监控是每1分钟监控一次,然后1分钟内redis完成了异常关闭和守护进程重启的完整流程,下次监控周期,alive还是正常。所以最靠谱的办法是多个维度监控:例如再结合监控pid是否改变过,下面汇总下一些常见需求和指标:
1 monitor if process be restarted:
process_id:14330
or check uptime_in_seconds if be 0.
2 速率
Redis_instantaneous_ops_per_sec
3 连接客户端数
Redis_connected_clients “gauge”