其实说起性能调优,我们往往有很多理论依据可以参考,例如针对分布式系统的NWR、CAP等,也有很多实践的“套路”,如绘制火焰图、监控调用链等。实际上,不管方式、方法有多少,我们的终极目标都是一致的,那就是在固定的资源条件下,将系统的响应速度调整到极致。
但是在严谨地评价一个系统性能时,我们很少粗略地使用这种表述:在压力A(如1000 TPS)下,基于软硬件配置B,我们应用的C操作响应时间是D毫秒。而是加上一个百分位,例如:在压力A(如1000 TPS)下,基于软硬件配置B,我们应用的C操作响应时间99%已经达到D毫秒。或者当需要提供更为详细的性能报告时,我们提供的往往是类似于下面表格形式的数据来反映性能:不仅包括常见的百分比(95%、99%等或者常见的四分位),也包括平均数、中位数、最大值等。
那为什么要如此“严谨”?不可以直接说达到了某某水平吗?究其原因,还是我们的系统很难达到一个完美的极致,总有一些请求的处理时间超出了我们的“预期”,让我们的系统不够平滑(即常说的系统有“毛刺”)。所以在追求极致的路上,我们的工作重心已经不再是“大刀阔斧”地进行主动性能调优以满足99%的需求,而是着重观察、分析那掉队的1%请求,找出这些“绊脚石”,再各个击破,从而提高我们系统性能的“百分比”。例如,从2个9(99%)再进一步提高到3个9(99.9%)。而实际上,我们不难发现,这些所谓的绊脚石其实都是类似的,所以这期分享我就带你看看究竟有哪些绊脚石,我们结合具体场景总结应对策略。
场景1:重试、重定向
案例
当我们使用下游服务的API接口时,偶尔会出现延时较大的情况,而这些延时较大的调用最后也能成功,且没有任何明显的时间规律。例如响应延时正常时,API调用性能度量数据如下:
{
"stepName": "CallRemoteService"
"values": {
"componentType": "RemoteService",
"startTime": "2020-07-06T10:50:41.102Z",
"totalDurationInMS": 2,
"success": true
}
}
而响应延时超出预期时,度量数据如下:
{
"stepName": "CallRemoteService"
"values": {
"componentType": "RemoteService",
"startTime": "2020-07-06T04:31:55.805Z",
"totalDurationInMS": 2005,
"success": true
}
}
解析
这种情况可以说非常典型了,单从以上度量数据来看,没有什么参考意义,因为所有的性能问题都是这样的特征,即延时增大了。这里面可能的原因也有许多,例如GC影响、网络抖动等等,但是除了这些原因之外,其实最常见、最简单的原因往往都是发生了“重试”。重试成功前的访问往往都是很慢的,因为可能遇到了各种需要重试的错误,同时重试本身也会增加响应时间。那作为第一个绊脚石,我们现在就对它进行一个简单的分析。
以这个案例为例,经过查询后你会发现:虽然最终是成功的,但是我们中途进行了重试,具体而言就是我们在使用HttpClient访问下游服务时,自定义了重试的策略:当遇到ConnectTimeoutException、SocketTimeoutException等错误时直接进行重试。
//构建http client
CloseableHttpClient httpClient = HttpClients.custom().
setConnectionTimeToLive(3, TimeUnit.MINUTES).
//省略其它非关键代码
setServiceUnavailableRetryStrategy(new DefaultServiceUnavailableRetryStrategy(1, 50)).
//设置了一个自定义的重试规则
setRetryHandler(new CustomizedHttpRequestRetryHandler()).
build();
//自定义的重试规则
@Immutable
public class CustomizedHttpRequestRetryHandler implements HttpRequestRetryHandler {
private final static int RETRY_COUNT = 1;
CustomizedHttpRequestRetryHandler() {}
@Override
public boolean retryRequest(final IOException exception, final int executionCount, final HttpContext context) {
//控制重试次数
if (executionCount > RETRY_COUNT) {
return false;
}
//遇到下面这些异常情况时,进行重试
if (exception instanceof ConnectTimeoutException || exception instanceof NoHttpResponseException || exception instanceof SocketTimeoutException) {
return true;
}
//省略其它非关键代码
return false;
}
}
如果查询日志的话(由org.apache.http.impl.execchain.RetryExec#execute输出),我们确实发现了重试的痕迹,且可以完全匹配上我们的请求和时间:
[07/06/2020 04:31:57.808][threadpool-0]INFO RetryExec-I/O exception (org.apache.http.conn.ConnectTimeoutException) caught when processing request to {}->http://10.224.86.130:8080: Connect to 10.224.86.130:8080 [/10.224.86.130] failed: connect timed out
[07/06/2020 04:31:57.808][threadpool-0]INFO RetryExec-Retrying request to {}->http://10.224.86.130:8080
另外除了针对异常的重试外,我们有时候也需要对于服务的短暂不可用(返回503:SC_SERVICE_UNAVAILABLE)进行重试,正如上文贴出的代码中我们设置了DefaultServiceUnavailableRetryStrategy。
小结
这个案例极其简单且常见,但是这里我需要额外补充下:假设遇到这种问题,又没有明确给出重试的痕迹(日志等)时,我们应该怎么去判断是不是重试“捣鬼”的呢?
一般而言,我们可以直接通过下游服务的调用次数数据来核对是否发生了重试。但是如果下游也没有记录,在排除完其它可能原因后,我们仍然不能排除掉重试的原因,因为重试的痕迹可能由于某种原因被隐藏起来了,例如使用的开源组件压根没有打印日志,或者是打印了但是我们应用层的日志框架没有输出。这个时候,我们也没有更好的方法,只能翻阅源码查找线索。
另外除了直接的重试导致延时增加外,还有一种类似情况也经常发生,即“重定向”,而比较坑的是,对于重定向行为,很多都被“内置”起来了:即不输出INFO日志。例如Apache HttpClient对响应码3XX的处理(参考org.apache.http.impl.client.DefaultRedirectStrategy)只打印了Debug日志:
final String location = locationHeader.getValue();
if (this.log.isDebugEnabled()) {
this.log.debug("Redirect requested to location '" + location + "'");
}
再如,当我们使用Jedis访问Redis集群中的结点时,如果数据不在当前的节点了,也会发生“重定向”,而它并没有打印出日志让我们知道这件事的发生(参考redis.clients.jedis.JedisClusterCommand):
private T runWithRetries(final int slot, int attempts, boolean tryRandomNode, JedisRedirectionException redirect) {
//省略非关键代码
} catch (JedisRedirectionException jre) {
// if MOVED redirection occurred,
if (jre instanceof JedisMovedDataException) {
//此处没有输入任何日志指明接下来的执行会“跳转”了。
// it rebuilds cluster's slot cache recommended by Redis cluster specification
this.connectionHandler.renewSlotCache(connection);
}
//省略非关键代码
return runWithRetries(slot, attempts - 1, false, jre);
} finally {
releaseConnection(connection);
}
综上,重试是最普通的,也是最简单的导致延时增加的“绊脚石”,而重试问题的界定难度取决于自身和下游服务是否有明显的痕迹指明。而对于这种绊脚石的消除,一方面我们应该主动出击,尽量减少引发重试的因素。另一方面,我们一定要控制好重试,例如:
控制好重试的次数;
错峰重试的时间;
尽可能准确识别出重试的成功率,以减少不必要的重试,例如我们可以通过“熔断”“快速失败”等机制来实现。
场景2:失败引发轮询
案例
在使用Apache HttpClient发送HTTP请求时,稍有经验的程序员都知道去控制下超时时间,这样,在连接不上服务器或者服务器无响应时,响应延时都会得到有效的控制,例如我们会使用下面的代码来配置HttpClient:
RequestConfig requestConfig = RequestConfig.custom(). setConnectTimeout(2 * 1000). //控制连接建立时间 setConnectionRequestTimeout(1 * 1000).//控制获取连接时间 setSocketTimeout(3 * 1000).//控制“读取”数据等待时间 build();
以上面的代码为例,你能估算出响应时间最大是多少么?上面的代码实际设置了三个参数,是否直接相加就能计算出最大延时时间?即所有请求100%控制在6秒。
先不说结论,通过实际的生产线观察,我们确实发现大多符合我们的预期:可以说99.9%的响应都控制在6秒以内,但是总有一些“某年某月某天”,发现有一些零星的请求甚至超过了10秒,这又是为什么?
解析
经过问题跟踪,我们发现我们访问的URL是一个下游服务的域名(大多如此,并不稀奇),而这个域名本身有点特殊,由于负载均衡等因素的考虑,我们将它绑定到了多个IP地址。所以假设这些IP地址中,一些IP地址指向的服务临时不服务时,则会引发轮询,即轮询其它IP地址直到最终成功或失败,而每一次轮询中的失败都会额外增加一倍ConnectTimeout,所以我们发现超过6秒甚至10秒的请求也不稀奇了。我们可以通过HttpClient的源码来验证下这个逻辑(参考org.apache.http.impl.conn.DefaultHttpClientConnectionOperator.connect方法):
public void connect(
final ManagedHttpClientConnection conn,
final HttpHost host,
final InetSocketAddress localAddress,
final int connectTimeout,
final SocketConfig socketConfig,
final HttpContext context) throws IOException {
final Lookup registry = getSocketFactoryRegistry(context);
final ConnectionSocketFactory sf = registry.lookup(host.getSchemeName());
//域名解析,可能解析出多个地址
final InetAddress[] addresses = host.getAddress() != null ?
new InetAddress[] { host.getAddress() } : this.dnsResolver.resolve(host.getHostName());
final int port = this.schemePortResolver.resolve(host);
//对于解析出的地址,进行连接,如果中途有失败,尝试下一个
for (int i = 0; i < addresses.length; i++) {
final InetAddress address = addresses[i];
final boolean last = i == addresses.length - 1;
Socket sock = sf.createSocket(context);
conn.bind(sock);
final InetSocketAddress remoteAddress = new InetSocketAddress(address, port);
if (this.log.isDebugEnabled()) {
this.log.debug("Connecting to " + remoteAddress);
}
try {
//使用解析出的地址执行连接
sock = sf.connectSocket(
connectTimeout, sock, host, remoteAddress, localAddress, context);
conn.bind(sock);
if (this.log.isDebugEnabled()) {
this.log.debug("Connection established " + conn);
}
//如果连接成功,则直接退出,不继续尝试其它地址
return;
} catch (final SocketTimeoutException ex) {
if (last) {
throw new ConnectTimeoutException(ex, host, addresses);
}
} catch (final ConnectException ex) {
if (last) { //如果连接到最后一个地址,还是失败,则抛出异常。如果不是最后一个,则轮询下一个地址进行连接。
final String msg = ex.getMessage();
if ("Connection timed out".equals(msg)) {
throw new ConnectTimeoutException(ex, host, addresses);
} else {
throw new HttpHostConnectException(ex, host, addresses);
}
}
}
if (this.log.isDebugEnabled()) {
this.log.debug("Connect to " + remoteAddress + " timed out. " +
"Connection will be retried using another IP address");
}
}
}
通过以上代码,我们可以清晰地看出:在一个域名能解析出多个IP地址的场景下,如果其中部分IP指向的服务不可达时,延时就可能会增加。这里不妨再举个例子,对于Redis集群,我们会在客户端配置多个连接节点(例如在SpringBoot中配置spring.redis.cluster.nodes=10.224.56.101:8001,10.224.56.102:8001),通过连接节点来获取整个集群的信息(其它所有节点)。正常情况下,我们都会连接成功,所以我们没有看到长延时情况,但是假设刚初始化时,连接的部分节点不服务了,那这个时候就会连接其它配置的节点,从而导致延时倍增。
小结
这部分我们主要看了失败引发轮询造成的长延时案例,细心的同学可能会觉得这不就是上一部分介绍的重试么?但是实际上,你仔细体会,两者虽然都旨在提供系统可靠性,但却略有区别:重试一般指的是针对同一个目标进行的再次尝试,而轮询则更侧重对同类目标的遍历。
另外,除了以上介绍的开源组件(Apache HttpClient和RedisClient)案例外,还有其它一些常见组件都可能因为轮询而造成延时超过预期。例如对于Oracle连接,我们采用下面的这种配置时,也可能会出现轮询的情况:
DBURL=jdbc:oracle:thin:@(DESCRIPTION=(load_balance=off)(failover=on)(ADDRESS=(PROTOCOL=TCP)(HOST=10.224.11.91)(PORT=1804))(ADDRESS=(PROTOCOL=TCP)(HOST=10.224.11.92)(PORT=1804))(ADDRESS=(PROTOCOL=TCP)(HOST= 10.224.11.93)(PORT=1804))(CONNECT_DATA=(SERVICE_NAME=xx.yy.com)(FAILOVER_MODE=(TYPE=SELECT)(METHOD=BASIC)(RETRIES=6)(DELAY=5)))) DBUserName=admin DBPassword=password
其实通过对以上三个案例的观察,我们不难得出一个小规律:假设我们配置了多个同种资源时,那么很有可能存在轮询情况,这种轮询会让延时远超出我们的预期。只是幸运的是,在大多情况下,轮询第一次就成功了,所以我们很难观察到长延时的情况。针对这种情况造成的延时,我们除了在根源上消除外因,还要特别注意控制好超时时间,假设我们不知道这种情况,我们乐观地设置了一个很大的时间,则实际发生轮询时,这个时间会被放大很多倍。
这里再回到最开始的案例啰嗦几句,对于HttpClient的访问,是否加上最大轮询时间就是最大的延时时间呢?其实仍然不是,至少我们还忽略了一个时间,即DNS解析花费的时间。这里就不再展开讲了。
场景3:GC的“STW”停顿
案例
系统之间调用是服务最常见的方式,但这也是最容易发生“掐架”的斗争之地。例如对于组件A,运维或者测试工程师反映某接口偶然性能稍差,而对于这个接口而言,实际逻辑“简单至极”:直接调用组件B的接口。而对于这个接口的调用,平时确实都是接近1ms的:
[07/04/2020 07:18:16.495 pid=3160 tid=3078502112] Info:[ComponentA] Send to Component B: [07/04/2020 07:18:16.496 pid=3160 tid=3078502112] Info:[ComponentA] Receive response from B
而反映的性能掉队不经常发生,而且发生时,也没有没有特别的信息,例如下面这段日志,延时达到了400ms:
[07/04/2020 07:16:27.222 pid=4725 tid=3078407904] Info: [ComponentA] Send to Component B: [07/04/2020 07:16:27.669 pid=4725 tid=3078407904] Info: [ComponentA] Receive response from B
同时,对比下,我们也发现这2次请求其实很近,只有2分钟的差距。那么这又是什么导致的呢?
解析
对于这种情况,很明显,A组件往往会直接“甩锅”给B组件的。于是,B组件工程师查询了日志:
[07/04/2020 07:16:27.669][nioEventLoopGroup-4-1]INFO [ComponentB] Received request from Component A [07/04/2020 07:16:27.669][nioEventLoopGroup-4-1]INFO [ComponentB] Response to Component B
然后组件B也开始甩锅:鉴于我们双方组件传输层都是可靠的,且N年没有改动,那这次的慢肯定是网络抖动造成的了。貌似双方也都得到了理想的理由,但是问题还是没有解决,这种类似的情况还是时而发生,那问题到底还有别的什么原因么?
鉴于我之前的经验,其实我们早先就知道Java的STW(Stop The World)现象,可以说Java最省心的地方也是最容易让人诟病的地方。即不管怎么优化,或采用更先进的垃圾回收算法,都避免不了GC,而GC会引发停顿。其实上面这个案例,真实的原因确实就是B组件的GC导致了它的处理停顿,从而没有及时接受到A发出的信息,何以见得呢?
早先在设计B组件时,我们就考虑到未来某天可能会发生类似的事情,所以加了一个GC的跟踪日志,我们先来看看日志:
{
"metricName": "java_gc",
"componentType": "B",
"componentAddress": "10.224.3.10",
"componentVer": "1.0",
"poolName": "test001",
"trackingID": "269",
"metricType": "innerApi",
"timestamp": "2020-07-04T07:16:27.219Z",
"values": {
"steps": [
],
"totalDurationInMS": 428
}
}
在07:16:27.219时,发生了GC,且一直持续了428ms,所以最悲观的停顿时间是从219ms到647ms,而我们观察下A组件的请求发送时间222是落在这个区域的,再核对B组件接收这个请求的时间是669,是GC结束后的时间。所以很明显,排除其它原因以后,这明显是受了GC的影响。
小结
假设某天我们看到零星请求有“掉队”,且没有什么规律,但是又持续发生,我们往往都会怀疑是网络抖动,但是假设我们的组件是部署在同一个网络内,实际上,不大可能是网络原因导致的,而更可能是GC的原因。当然,跟踪GC有N多方法,这里我只是额外贴上了组件B使用的跟踪代码:
List gcbeans = ManagementFactory.getGarbageCollectorMXBeans();
for (GarbageCollectorMXBean gcbean : gcbeans) {
LOGGER.info("GC bean: " + gcbean);
if (!(gcbean instanceof NotificationEmitter))
continue;
NotificationEmitter emitter = (NotificationEmitter) gcbean;
//注册一个GC(垃圾回收)的通知回调
emitter.addNotificationListener(new NotificationListenerImplementation(), notification -> {
return GarbageCollectionNotificationInfo.GARBAGE_COLLECTION_NOTIFICATION
.equals(notification.getType());
}, null);
}
public final static class NotificationListenerImplementation implements NotificationListener {
@Override
public void handleNotification(Notification notification, Object handback) {
GarbageCollectionNotificationInfo info = GarbageCollectionNotificationInfo
.from((CompositeData) notification.getUserData());
String gctype = info.getGcAction().replace("end of ", "");
//此处只获取major gc的相关信息
if(gctype.toLowerCase().contains("major")){
long id = info.getGcInfo().getId();
long startTime = info.getGcInfo().getStartTime();
long duration = info.getGcInfo().getDuration();
//省略非关键代码,记录GC相关信息,如耗费多久、开始时间点等。
}
}
}
另外同样是停顿,发生的时机不同,呈现的效果也不完全相同,具体问题还得具体分析。至于应对这个问题的策略,就是我们写Java程序一直努力的方向:减少GC引发的STW时间。
场景4:资源争用
案例
一段时间,我们总是监控到一些性能“掉队”的请求,例如平时我们访问Cassandra数据库都在10ms以内,但是偶尔能达到3s,你可以参考下面这个度量数据:
{
"stepName": "QueryInformation",
"values": {
"componentType": "Cassandra",
"totalDurationInMS": 3548,
"startTime": "2018-05-11T08:20:28.889Z",
"success": true
}
}
持续观察后,我们发现这些掉队的请求都集中在每天8点20分,话说“百果必有因”,这又是什么情况呢?
解析
这种问题,其实相对好查,因为它们有其发生的规律,这也是我们定位性能问题最基本的手段,即找规律:发生在某一套环境?某一套机器?某个时间点?等等,这些都是非常有用的线索。而这个案例就是固定发生在某个时间点。既然是固定时间点,说明肯定有某件事固定发生在这个点,所以查找问题的方向自然就明了了。
首先,我们上来排除了应用程序及其下游应用程序定时去做任务的情况。那么除了应用程序自身做事情外,还能是什么?可能我们会想到:运行应用程序的机器在定时做事情。果然,我们查询了机器的CronJob,发现服务器在每天的8点20分(业务低峰期)都会去归档业务的日志,而这波集中的日志归档操作,又带来了什么影响呢?
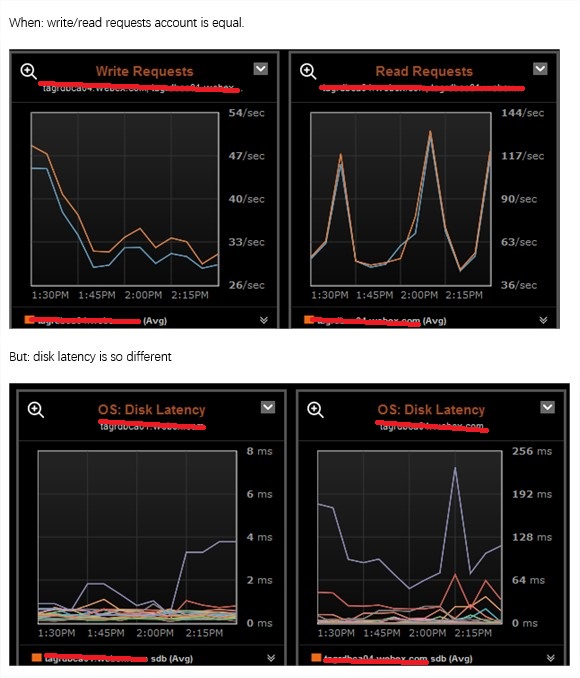
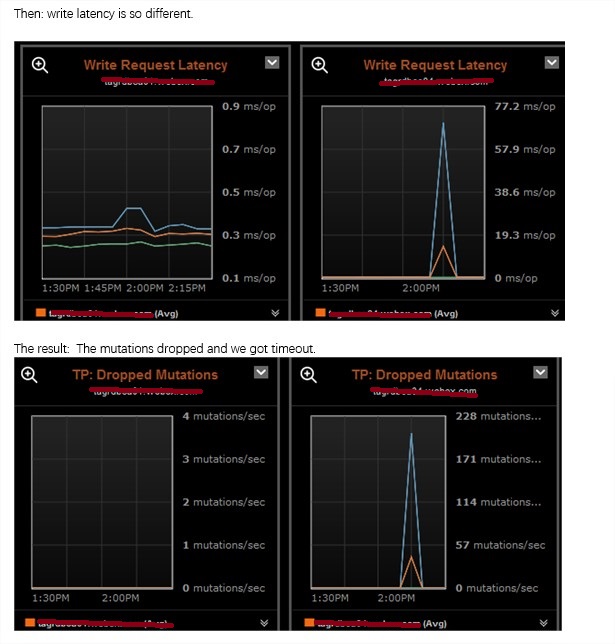
日志备份明显是磁盘操作,所以我们要查看的是磁盘的性能影响,如果磁盘都转不动了,可想而知会引发什么。我们一般都会有图形化的界面去监控磁盘性能,但是这里为了更为通用的演示问题,所以我使用了SAR的结果来展示当时的大致情况(说是大致,是因为SAR的历史记录结果默认是以10分钟为间隔,所以只显示8:20分的数据,可能8:21分才是尖峰,但是却不能准确反映):

DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 08:10:01 AM dev8-0 3.69 0.00 95.72 25.98 0.01 2.38 0.97 0.36 08:20:01 AM dev8-0 4.95 0.03 627.15 126.75 1.09 219.38 11.49 5.69 08:30:01 AM dev8-0 3.00 0.00 68.34 22.80 0.01 2.38 1.21 0.36
从上面的结果我们可以看出,平时磁盘await只要2ms,而8:20分的磁盘操作达到了几百毫秒。磁盘性能的急剧下降影响了应用程序的性能。
小结
在这个案例中,服务器上的定时日志归档抢占了我们的资源,导致应用程序速度临时下降,即资源争用导致了性能掉队。我们再延伸一点来看,除了这种情况外,还有许多类似的资源争用都有可能引起这类问题,例如我们有时候会在机器上装一些logstash、collectd等监控软件,而这些监控软件如果不限制它们对资源的使用,同样也可能会争用我们很多的资源。诸如此类,不一一枚举,而针对这种问题,很明显有好几种方法可以供我们去尝试解决,以当前的案例为例:
降低资源争用,例如让备份慢一点;
错峰,错开备份时间,例如不让每个机器都是8点20分去备份,而是在大致一个时间范围内随机时间进行;
避免资源共享,避免多个机器/虚拟机使用同一块磁盘。
上面讨论的争用都发生在一个机器内部,实际上,资源争用也常发生在同一资源(宿主、NFS磁盘等)的不同虚拟机之间,这也是值得注意的一个点。
场景5:延时加载
案例
某日,某测试工程师胸有成竹地抱怨:“你这个API接口性能不行啊,我们每次执行自动化测试时,总有响应很慢的请求。”于是一个常见的争执场景出现了:当面演示调用某个API若干次,结果都是响应极快,测试工程师坚持他真的看到了请求很慢的时候,但是开发又坚定说在我的机器上它就是可以啊。于是互掐不停。

解析
开发者后来苦思冥想很久,和测试工程师一起比较了下到底他们的测试有什么不同,唯一的区别在于测试的时机不同:自动化测试需要做的是回归测试,所以每次都会部署新的包并执行重启,而开发者复现问题用的系统已经运行若干天,那这有什么区别呢?这就引入了我们这部分要讨论的内容——延时加载。
我们知道当系统去执行某个操作时,例如访问某个服务,往往都是“按需执行”,这非常符合我们的行为习惯。例如,需要外卖点餐时,我们才打开某APP,我们一般不会在还没有点餐的时候,就把APP打开“守株待兔”某次点餐的发生。这种思路写出来的系统,会让我们的系统在上线之时,可以轻装上阵。例如,非常类似下面的Java“延时初始化”伪代码:
public class AppFactory{
private static App app;
synchronized App getApp() {
if (App == null)
app= openAppAndCompleteInit();
return app;
}
//省略其它非关键代码
}
App app = AppFactory.getApp();
app.order("青椒土豆丝");
但这里的问题是什么呢?假设打开APP的操作非常慢,那等我们需要点餐的时候,就会额外耗费更长的时间(而一旦打开运行在后台,后面不管怎么点都会很快)。这点和我们的案例其实是非常类似的。
我们现在回到案例,持续观察发现,这个有性能问题的API只出现在第一次访问,或者说只出现在系统重启后的第一次访问。当它的API被触发时,它会看看本地有没有授权相关的信息,如果没有则远程访问一个授权服务拿到相关的认证信息,然后缓存认证信息,最后再使用这个认证信息去访问其它组件。而问题恰巧就出现在访问授权服务器完成初始化操作耗时
比较久,所以呈现出第一次访问较慢,后续由于已缓存消息而变快的现象。
那这个问题怎么解决呢?我们可以写一个“加速器”,说白了,就是把“延时加载”变为“主动加载”。在系统启动之后、正常提供服务之前,就提前访问授权服务器拿到授权信息,这样等系统提供服务之后,我们的第一个请求就很快了。类似使用Java伪代码,对上述的延时加载修改如下:
public class AppFactory{
private static App app = openAppAndCompleteInit();
synchronized App getApp() {
return app;
}
//省略其它非关键代码
}
小结
延时加载固然很好,可以让我们的系统轻装上阵,写出的程序也符合我们的行为习惯,但是它常常带来的问题是,在第一次访问时可能性能不符合预期。当遇到这种问题时,我们也可以根据它的出现特征来分析是不是属于这类问题,即是否是启动完成后的第一次请求。如果是此类问题,我们可以通过变“被动加载”为“主动加载“的方式来加速访问,从而解决问题。
但是这里我不得不补充一点,是否在所有场景下,我们都需要化被动为主动呢?实际上,还得具体情况具体分析,例如我们打开一个网页,里面内嵌了很多小图片链接,但我们是否会为了响应速度,提前将这些图片进行加载呢?一般我们都不会这么做。所以具体问题具体分析永远是真理。针对我们刚刚讨论的案例,这种加速只是一次性的而已,而且资源数量和大小都是可控的,所以这种修改是值得,也是可行的。
<strong>场景6:网络抖动</strong>
案例
我们来看一则新闻:
<a href="http://www.strolling.cn/wp-content/uploads/2020/12/7.jpg"><img class="alignnone size-full wp-image-1919" src="http://www.strolling.cn/wp-content/uploads/2020/12/7.jpg" alt="" width="1550" height="564" /></a>
类似的新闻还有许多,你可以去搜一搜,然后你就会发现:它们都包含一个关键词——网络抖动。
解析
那什么是网络抖动呢?网络抖动是衡量网络服务质量的一个指标。假设我们的网络最大延迟为100ms,最小延迟为10ms,那么网络抖动就是90ms,即网络延时的最大值与最小值的差值。差值越小,意味着抖动越小,网络越稳定。反之,当网络不稳定时,抖动就会越大,网络延时差距也就越大,反映到上层应用自然是响应速度的“掉队”。
为什么网络抖动如此难以避免?这是因为网络的延迟包括两个方面:传输延时和处理延时。忽略处理延时这个因素,假设我们的一个主机进行一次服务调用,需要跨越千山万水才能到达服务器,我们中间出“岔子”的情况就会越多。我们在Linux下面可以使用traceroute命令来查看我们跋山涉水的情况,例如从我的Linux机器到百度的情况是这样的:
[root@linux~]# traceroute -n -T www.baidu.com
traceroute to www.baidu.com (119.63.197.139), 30 hops max, 60 byte packets
1 10.224.2.1 0.452 ms 0.864 ms 0.914 ms
2 1.1.1.1 0.733 ms 0.774 ms 0.817 ms
3 10.224.16.193 0.361 ms 0.369 ms 0.362 ms
4 10.224.32.9 0.355 ms 0.414 ms 0.478 ms
5 10.140.199.77 0.400 ms 0.396 ms 0.544 ms
6 10.124.104.244 12.937 ms 12.655 ms 12.706 ms
7 10.124.104.195 12.736 ms 12.628 ms 12.851 ms
8 10.124.104.217 13.093 ms 12.857 ms 12.954 ms
9 10.112.4.65 12.586 ms 12.510 ms 12.609 ms
10 10.112.8.222 44.250 ms 44.183 ms 44.174 ms
11 10.112.0.122 44.926 ms 44.360 ms 44.479 ms
12 10.112.0.78 44.433 ms 44.320 ms 44.508 ms
13 10.75.216.50 44.295 ms 44.194 ms 44.386 ms
14 10.75.224.202 46.191 ms 46.135 ms 46.042 ms
15 119.63.197.139 44.095 ms 43.999 ms 43.927 ms
通过上面的命令结果我们可以看出,我的机器到百度需要很多“路”。当然大多数人并不喜欢使用traceroute来评估这段路的艰辛程度,而是直接使用ping来简单看看“路”的远近。例如通过以下结果,我们就可以看出,我们的网络延时达到了40ms,这时网络延时就可能是一个问题了。
[root@linux~]# ping www.baidu.com
PING www.wshifen.com (103.235.46.39) 56(84) bytes of data.
64 bytes from 103.235.46.39: icmp_seq=1 ttl=41 time=46.2 ms
64 bytes from 103.235.46.39: icmp_seq=2 ttl=41 time=46.3 ms
其实上面这两个工具的使用只是直观反映网络延时,它们都默认了一个潜规则:网络延时越大,网络越抖动。且不说这个规则是否完全正确,至少从结果来看,评估网络抖动并不够直观。
所以我们可以再寻求一些其它的工具。例如可以使用MTR工具,它集合了tractroute和ping。我们可以看下执行结果:下图中的best和wrst字段,即为最好的情况与最坏的情况,两者的差值也能在一定程度上反映出抖动情况,其中不同的host相当于traceroute经过的“路”。
小结
对于网络延时造成的抖动,特别是传输延迟造成的抖动,我们一般都是“有心无力”的。只能说,我们需要做好网络延时的抖动监测,从而能真正定位到这个问题,避免直接无证据就“甩锅”于网络。
另外,在做设计和部署时,我们除了容灾和真正的业务需求,应尽量避免或者说减少“太远”的访问,尽量将服务就近到一个机房甚至一个机柜,这样就能大幅度降低网络延迟,抖动情况也会降低许多,这也是为什么CDN等技术兴起的原因。
那同一网络的网络延时可以有多好呢?我们可以自己测试下。例如,我的Linux机器如果ping同一个网段的机器,是连1ms都不到的:
[root@linux~]# ping 10.224.2.146
PING 10.224.2.146 (10.224.2.146) 56(84) bytes of data.
64 bytes from 10.224.2.146: icmp_seq=1 ttl=64 time=0.212 ms
64 bytes from 10.224.2.146: icmp_seq=2 ttl=64 time=0.219 ms
64 bytes from 10.224.2.146: icmp_seq=3 ttl=64 time=0.154 ms
场景7:缓存失效
案例
在产线上,我们会经常观察到一些API接口调用周期性(固定时间间隔)地出现“长延时”,而另外一些接口调用也会偶尔如此,只是时间不固定。继续持续观察,你会发现,虽然后者时间不够规律,但是它们的出现时间间隔都是大于一定时间间隔的。那这种情况是什么原因导致的呢?
解析
当我们遇到上述现象,很有可能是因为“遭遇”了缓存失效。缓存的定义与作用这里不多赘述,你应该非常熟悉了。同时我们也都知道,缓存是以空间换时间的方式来提高性能,讲究均衡。在待缓存内容很多的情况下,不管我们使用本地缓存,还是Redis、Memcached等缓存方案,我们经常都会受限于“空间”或缓存条目本身的时效性,而给缓存设置一个失效时间。而当失效时间到来时,我们就需要访问数据的源头从而增加延时。这里以下面的缓存构建代码作为示例:
CacheBuilder.newBuilder().maximumSize(10_000).expireAfterWrite(10, TimeUnit.MINUTES).build();
我们可以看到:一旦缓存后,10分钟就会失效,但是失效后,我们不见得刚好有请求过来。如果这个接口是频繁调用的,则长延时请求的出现频率会呈现出周期性的10分钟间隔规律,即案例描述的前者情况。而如果这个接口调用很不频繁,则我们只能保证在10分钟内的延时是平滑的。当然,这里讨论的场景都是在缓存够用的情况下,如果缓存的条目超过了设定的最大允许值,这可能会提前淘汰一些缓存内容,这个时候长延时请求出现的规律就无章可循了。
小结
缓存失效是导致偶发性延时增加的常见情况,也是相对来说比较好定位的问题,因为接口的执行路径肯定是不同的,只要我们有充足的日志,即可找出问题所在。另外,针对这种情况,一方面我们可以增加缓存时间来尽力减少长延时请求,但这个时候要求的空间也会增大,同时也可能违反了缓存内容的时效性要求;另一方面,在一些情况下(比如缓存条目较少、缓存的内容可靠性要求不高),我们可以取消缓存的TTL,更新数据库时实时更新缓存,这样读取数据就可以一直通过缓存进行。总之,应情况调整才是王道。
总结
上面是总结的7种常见“绊脚石”及其应对策略,那通过了解它们,我们是否就有十足的信心能达到性能巅峰了呢?
其实在实践中,我们往往还是很难的,特别是当前微服务大行其道,决定我们系统性能的因素往往是下游微服务,而下游微服务可能来源于不同的团队或组织。这时,已经不再单纯是技术本身的问题了,而是沟通、协调甚至是制度等问题。但是好在对于下游微服务,我们依然可以使用上面的分析思路来找出问题所在,不过通过上面的各种分析你也可以知道,让性能做到极致还是很难的,总有一些情况超出我们的预期,例如我们使用的磁盘发生损害,彻底崩溃前也会引起性能下降。
另外一个值得思考的问题是,是否有划算的成本收益比去做无穷无尽的优化,当然对于技术极客来说,能不能、让不让解决问题也许不是最重要的,剥丝抽茧、了解真相才是最有成就感的事儿。