现象:
应用在某个时间点有5分钟左右的不可用造成了大量业务zookeeper操作失败。
原因分析:
首先观察指标:
检查epoch指标可以确定是否发生了选举:可以看到epoch从91改成了92

检查zxid指标,可以看出发生了溢出: 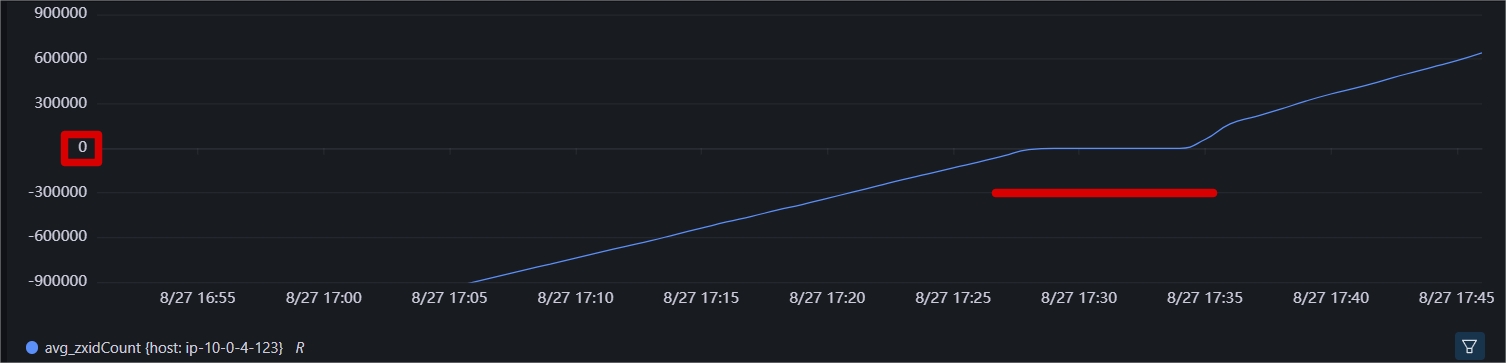
根据以上两个指标,基本上可以锁定发生了zxid溢出导致的leader重新选举,而选举时,集群不可用,这点可以参考zk的server日志可以核实。
2023-08-27 17:28:55,806 [myid:37] - INFO [nioEventLoopGroup-7-10:NettyServerCnxn@525] - Closing connection to /10.24.15.252:47146 because the server is not ready 2023-08-27 17:28:55,834 [myid:37] - INFO [nioEventLoopGroup-7-13:NettyServerCnxn@525] - Closing connection to /10.14.12.141:44252 because the server is not ready
那么zxid是什么,为什么它会溢出?溢出后的后果?这里可以简单分析下,在分析之前,登录服务器确认了下确实是zxid溢出问题:
Shutdown called. For the reason zxid lower 32 bits have rolled over, forcing re-election, and therefore new epoch start
确认问题无误后,可以解析下这个zxid功能:
为了保证事务的顺序一致性,Zookeeper 采用了递增的事务ID号(即zxid)来标识事务,所有的操作( proposal )都会在被提出时加上zxid,zxid是一个64位的数字:高32位是epoch用来标识leader关系是否发生变化,每当有新的leader 被选举出来,都会有一个新的epoch,标识当前属于多少代领导时期。例如高位为92,则可以简单理解为第92代“皇帝”。这个可以像前文提及的通过JMX的指标epoch变化来看是否发生了选举。后32位可以理解为在这个朝代发生的事务。事务这里其实就是改变zk的行为,所以像读取操作并不是一种事务。
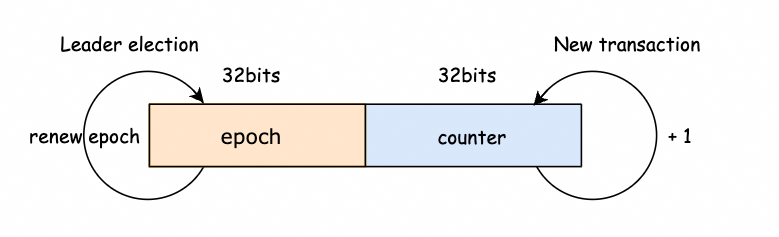
当改变zk行为的请求过来时,zk都是会让Leader来处理,而Leader处理的第一件事就是将这个请求(request)转化为一个“事务”来做。这种转化做的非常重要的一件事就是产生一个Id给通过设置TxnHeader的方式给它(request)(注意下:Follower之类的非leader不会产生zxid)。这样为后续事务的处理的有序性都提供了保障。可以参考下面代码看下请求的zxid设置过程:
org.apache.zookeeper.server.PrepRequestProcessor#pRequestHelper:
private void pRequestHelper(Request request) {
try {
switch (request.type) {
case OpCode.createContainer:
case OpCode.create:
case OpCode.create2:
CreateRequest create2Request = request.readRequestRecord(CreateRequest::new);
pRequest2Txn(request.type, zks.getNextZxid(), request, create2Request);
break;
其中zks.getNextZxid()即为取递增的Id:
org.apache.zookeeper.server.ZooKeeperServer#getNextZxid:
long getNextZxid() {
return hzxid.incrementAndGet();
}
这个id本身是递增的,所以一定会溢出,当溢出后,在leader处理到会发生溢出的请求时会遇到抛出异常
org.apache.zookeeper.server.quorum.Leader#propose:
public Proposal propose(Request request) throws XidRolloverException {
if ((request.zxid & 0xffffffffL) == 0xffffffffL) {
String msg = "zxid lower 32 bits have rolled over, forcing re-election, and therefore new epoch start";
shutdown(msg);
throw new XidRolloverException(msg);
}
而一旦抛出异常,最后代码的处理是关闭leader,然后触发重新选举。从而新的一轮选举就此发生。在选举成功这段期间,服务并不可用,最终成功时会输出下面这样的日志:
2023-08-27 17:34:23,137 [myid:37] - INFO [QuorumPeer[myid=37](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):ZooKeeperServer@361] - Created server with tickTime 2000 minSessionTimeout 4000 maxSessionTimeout 40000 clientPortListenBacklog -1 datadir /data/zooke eper/version-2 snapdir /data/zookeeper/version-2 2023-08-27 17:34:23,138 [myid:37] - INFO [QuorumPeer[myid=37](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):Leader@584] - LEADING - LEADER ELECTION TOOK - 342465 MS
通过这个日志可以看出选举花了多久,例如上面花了约6分钟,这也意味着服务不可用达6分钟。
问题解决:
通过上面的分析可知,zk的zxid是必然发生的问题,那么遇到这个问题的时候,我们可以先做两个方面的评估:
(1)每次影响时间是多少,上面已经统计这点可以通过日志直接获取这样的数据;本应用约为6分钟。
(2)发生的频率是多少,通过原理分析,很容易知道,这取决于业务的请求量大小。例如对于本应用,可以通过查询最近2次发生的日志的时间来推断,如果日志没有保存很久,也可以通过zxid指标的增长速度来估算。
例如取1周的变化数据(不考虑业务的月/季度变化):
time: 2023-09-01 03:00:00 zxid {host: ip-10-0-4-123}: 280105949.2
time: 2023-09-08 00:00:00 zxid {host: ip-10-0-4-123}: 692368820.8
由上述数据可以:一周4.2亿,每天0.6亿。
以zxid最多承接多少id,除以每天即为粗略的溢出间隔4294967296 ÷ 60000000 = 约71(天)
综合评估下,就是每2-3月会发生一次,每次影响约5-6分钟。
那么如何解决或者说缓和这个问题呢,无非以下思路:
(1)延缓发生的时间,例如可以减少必须要的业务请求量。再则网上也有人做过一种改进,修改zookeeper的代码重新打包,具体修改是将64位的后32位Id调整为更多位数,可行性是基于选举是小概率事件,不需要前32位那么多。不过个人认为,这种修改对以后的升级维护很不友好。
(2)减少影响的时间,也就是考虑如何减少选举的时间,例如对本应用而言,其实是7个Node,都是Follower角色,是不是可以将少许Follower转化为Observer来启动,这样参与选举的节点就少了,选举自然也会快些。这里还需要验证下。
当然,除了直接的方法外,还有一些其他间接的方法,例如减少对zk的依赖或者换其他存储,这里不做过多展开。
题外:
这里再补充一些这个问题定位时的弯路分析,在开始遇到这个问题时,实际上通过流量的变化(org.apache.zookeeper.server.ServerStats#packetsReceived对应的JMX指标)发现的,例如下图:
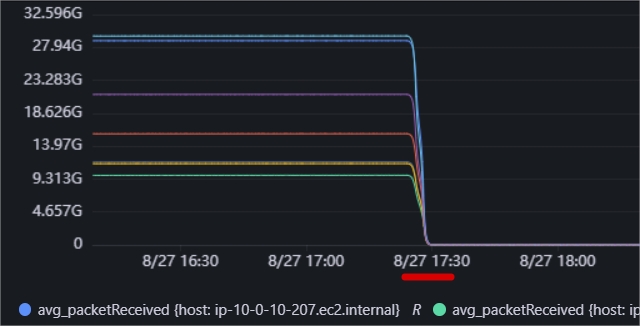
当时可视化系统也没有展示上文描述的2个重要指标,所以当时的第一感觉肯定是服务器发生了重启,因为这个统计指标表明的是zk接受到的包的总和,正常都是一直持续增加的,忽然归0,就很容易觉得是重启了。但是通过linux的last命令查看发生问题的世间点并没有人来操作,系统的日志也没有提示任何重启:
//last执行效果: [root@ip-10-0-0-247 user]# last |more user pts/1 38.99.100.2 Mon Sep 11 01:06 still logged in user pts/1 38.99.100.2 Fri Sep 8 06:15 - 10:25 (04:09) stroller. pts/3 38.99.100.2 Thu Sep 7 02:24 - 06:40 (04:16)
后来经过源码研究发现,其实这个指标归0除了zk重启外,还有2种情况,这2种情况不会重启zk:
(1) 四字命令srst的执行:
public static class StatResetCommand extends GetCommand {
public StatResetCommand() {
super(Arrays.asList("stat_reset", "srst"));
}
@Override
public CommandResponse runGet(ZooKeeperServer zkServer, Map<String, String> kwargs) {
CommandResponse response = initializeResponse();
zkServer.serverStats().reset();
return response;
}
}
(2)遇到zxid溢出等错误,导致shutdown并引发重新选举,就本案例而言,这个时候,相当于把leader给先关闭了,然后重新获取一个新的角色提供服务(LeaderZooKeeperServer/FollowerZooKeeperServer等)。这个新服务对像的指标数据存储对象(父类对象ZooKeeperServer#serverStats)就是初始化状态。总体来说:这里就等于在不关闭java进程的情况下做了“重启”。
这点也可以从前面贴出的两条日志得到严重,先shutdown,后重新创建了zk server:
//新的server: 2023-08-27 17:34:23,137 [myid:37] - INFO [QuorumPeer[myid=37](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):ZooKeeperServer@361] - Created server with tickTime 2000 minSessionTimeout 4000 maxSessionTimeout 40000 clientPortListenBacklog -1 datadir /data/zookeeper/version-2 snapdir /data/zookeeper/version-2
另外,ServerStats#packetsReceived很可能被理解为数据包个数,从而发生这样的误会:例如,一个请求可能拆分成两个数据包,那么packetsReceived是2,实际上,packetsReceived可以理解为请求数。参考代码 NettyServerCnxn#receiveMessage:
receiveMessage中的关键逻辑:
if (bb.remaining() == 0) { //请求的数据读完整时(读取了len长度)符合条件。
bb.flip();
//调用metrics
packetReceived(4 + bb.remaining());
//转化为请求然后进行后续处理
RequestHeader h = new RequestHeader();
ByteBufferInputStream.byteBuffer2Record(bb, h);
RequestRecord request = RequestRecord.fromBytes(bb.slice());
zks.processPacket(this, h, request);
}
//metris调用方法
protected void packetReceived(long bytes) {
ServerStats serverStats = serverStats();
if (serverStats != null) {
serverStats().incrementPacketsReceived();
//调用packetsReceived.incrementAndGet(),对应packetsReceived
}
ServerMetrics.getMetrics().BYTES_RECEIVED_COUNT.add(bytes);
//对应bytes_received_count
}
所以虽然查看问题,绕了弯路,但是也可以学习到更多知识。对出现问题的时如何看懂各种数据有了很多帮忙。