在学习metric之前,需要对metric领域涉及的基本概念有个初步的整体认识:
一 统计学指标:
以下面一段Cassandra的metric做示例:
Cassandra Metrics
Timer:
name=requests, count=171396, min=0.480973, max=4.228569, mean=1.0091534824902724, stddev=0.3463516148968051, median=0.975965, p75=1.1458145, p95=1.4784138999999996, p98=1.6538238999999988, p99=2.185363660000002, p999=4.22124273, mean_rate=0.0, m1=0.0, m5=0.0, m15=0.0, rate_unit=events/millisecond, duration_unit=milliseconds
1.1 集中量
(1)最大值、最小值、平均数:容易理解,不做赘述,即例子中的min=0.480973, max=4.228569,mean=1.0091534824902724,表明最小、最大和平均响应时间;
(2)中位数:一个样本、种群或概率分布中的一个数值,用它可以讲所有数据划分为相等的上下两部分。对于有限的数集,可以通过把所有观察值高低排序后找出正中间的一个作为中位数。如果数据总数是偶数个,通常取最中间的两个数值的平均数作为中位数。如示例中的median=0.975965,代表所有响应时间中最中间的那个数字,可见和平均数(mean=1.0091534824902724)并不相等。
1.2 差异量
(1)全距:将上述的最大值减去最小值即为全距,代表变化的范围,数值越大,说明数据越分散。例子中即为3.747596(max-min),数据跨度并不大;
(2)方差:每个样本值与全体样本值的平均数之差的平方值的平均数,用来度量随机变量和其数学期望(即均值)之间的偏离程度. 数值越小,表明数据分布越集中,例子中即为stddev=0.3463516148968051,表明数据相对很集中。
1.3 地位量
(1)分位数:分位数是将总体的全部数据按大小顺序排列后,处于各等分位置的变量值。例如上面的p95, p999都是这种概念。例如p999=4.22124273,代表99.9%的请求响应时间不大于4.22124273ms;
(2)四分位数:如果分成四等分,就是四分位数;八等分就是八分位数等。四分位数也称为四分位点,它是将全部数据分成相等的四部分,其中每部分包括25%的数据,处在各分位点的数值就是四分位数。四分位数有三个,第一个四分位数就是通常所说的四分位数,称为下四分位数,第二个四分位数就是中位数,第三个四分位数称为上四分位数,分别用Q1、Q2、Q3表示 [1] 。
第一四分位数 (Q1),又称”较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。
第二四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字,即median=0.975965。
第三四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字, 例如p75=1.1458145
二 相关的术语
2.1 QPS/TPS/PV/
QPS: Query Per Second每秒的查询次数;
TPS: Transaction per second 每秒的业务量;
PV: page view: 即文章的浏览量,常用于web服务器页面的统计。
2.2 度量类型
(1) Counter
代表一个递增的值,例如请求数,在server正常运行时,只会增加不会减少,在重启时会归0,例如:Cassandra的metric中的下列指标,都是只增不减,重启归0的值。
Counters:
name=client-timeouts, count=0
name=connection-errors, count=0
name=ignores, count=0
name=ignores-on-write-timeout, count=0
name=other-errors, count=0
name=read-timeouts, count=0
name=retries, count=0
name=speculative-executions, count=0
name=unavailables, count=0
name=write-timeouts, count=0
(2) Gauge
代表一个变化的值,表明是个瞬间的值。例如温度等可变化因素,下例中的Cassandra的metric值都是可以变化:
GAUGE:
name=blocking-executor-queue-depth, value=0
name=connected-to, value=7
name=executor-queue-depth, value=0
name=known-hosts, value=36
name=open-connections, value=8
name=reconnection-scheduler-task-count, value=0
name=task-scheduler-task-count, value=1
name=trashed-connections, value=0
(3) Histogram
即直方图: 主要使用来统计数据的分布情况,最大值、最小值、平均值、中位数,百分比(75%、90%、95%、98%、99%和99.9%)
count=171396, min=0.480973, max=4.228569, mean=1.0091534824902724, stddev=0.3463516148968051, median=0.975965, p75=1.1458145, p95=1.4784138999999996, p98=1.6538238999999988, p99=2.185363660000002, p999=4.22124273
注意关于百分比的相关参数并不是实际整个server运行期间的百分比,而是基于一定的统计方法来计算的值,试想,不可能存储所有的请求的数据,只能从时间和空间两个维度来推算。
例如:
com.codahale.metrics.SlidingWindowReservoir
package com.codahale.metrics;</code>
import static java.lang.Math.min;
/**
* A {@link Reservoir} implementation backed by a sliding window that stores the last {@code N}
* measurements.
*/
public class SlidingWindowReservoir implements Reservoir {
private final long[] measurements;
private long count;
/**
* Creates a new {@link SlidingWindowReservoir} which stores the last {@code size} measurements.
*
* @param size the number of measurements to store
*/
public SlidingWindowReservoir(int size) {
this.measurements = new long[size];
this.count = 0;
}
@Override
public synchronized int size() {
return (int) min(count, measurements.length);
}
@Override
public synchronized void update(long value) {
measurements[(int) (count++ % measurements.length)] = value;
}
@Override
public Snapshot getSnapshot() {
final long[] values = new long[size()];
for (int i = 0; i < values.length; i++) {
synchronized (this) {
values[i] = measurements[i];
}
}
return new Snapshot(values);
}
}
(4) Meters
用来度量某个时间段的平均处理次数(request per second),每1、5、15分钟的TPS。比如一个service的请求数,统计结果有总的请求数,平均每秒的请求数,以及最近的1、5、15分钟的平均TPS:
mean_rate=0.0, m1=0.0, m5=0.0, m15=0.0, rate_unit=events/millisecond, duration_unit=milliseconds
(5) Timer
主要是用来统计某一块代码段的执行时间以及其分布情况,具体是基于Histograms和Meters来实现的,所以结果是上面两个指标的合并结果。
三 Metric处理的一些术语:
3.1 Event time / Ingestion time / Processing Time
在流程序中支持不同概念的时间。以读取一条存储在kafka中的数据为例,存在多个时间字段:
Tue Jul 03 11:02:20 CST 2018 offset = 1472200, key = null, value = {"path":"/opt/application/logs/metrics_07012018_0.24536.log","component":"app","@timestamp":"2018-07-01T03:14:53.982Z","@version":"1","host":"10.224.2.116","eventtype":"metrics","message":{"componentType":"app","metricType":"innerApi","metricName":"demo","componentAddress":"10.224.57.67","featureName":"PageCall","componentVer":"2.2.0","poolName":"test","trackingID":"0810823d-dc92-40e4-8e9a-18774d549e21","timestamp":"2018-07-01T03:14:53.728Z"}}
Event time: 是事件发生的时间,而不考虑事件记录通过什么系统、什么时候到达、以什么样的顺序到达等因素。上例中2018-07-01T03:14:53.728Z即为server日志产生的时间;相当于邮寄快递时的邮寄时间。
Ingestion time:即摄入时间,是事件进入Metric系统的时间,在源操作中每个记录都会获得源的当前时间作为时间戳,当一个metric经过n条系统时,相对每条进入的数据,摄入时间就会存在多个。上例中的”@timestamp”:”2018-07-01T03:14:53.982Z”即为logstash获取这个server log的时间。相当于邮寄快递时,快递员的揽收时间。
Processing Time: 是处理系统开始处理某个事件的时间,上例中“Tue Jul 03 11:02:20 CST”为处理时间。相当于邮寄快递中的签收时间。
明确各种时间概率后,可见事件时间是最重要的。
3.2 tulbmimg window / hop window / session window
(1) Tumbling windows
Tumbling即翻跟头的意思,窗口不可能重叠的;在流数据中进行滚动,这种窗口不存在重叠,也就是说一个metric只可能出现在一个窗口中。
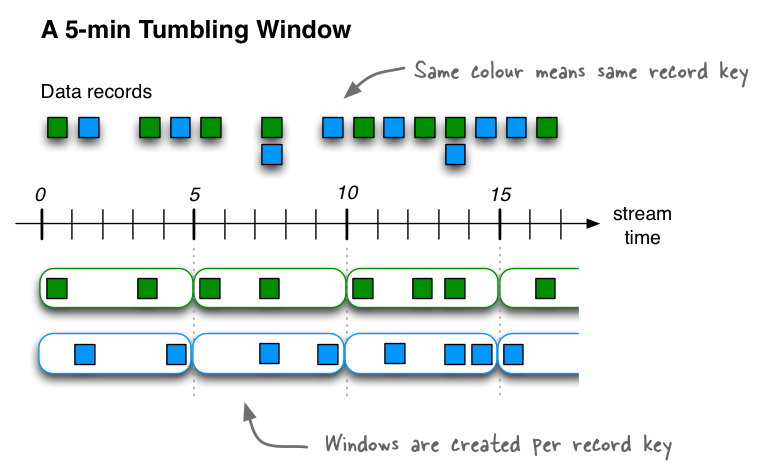
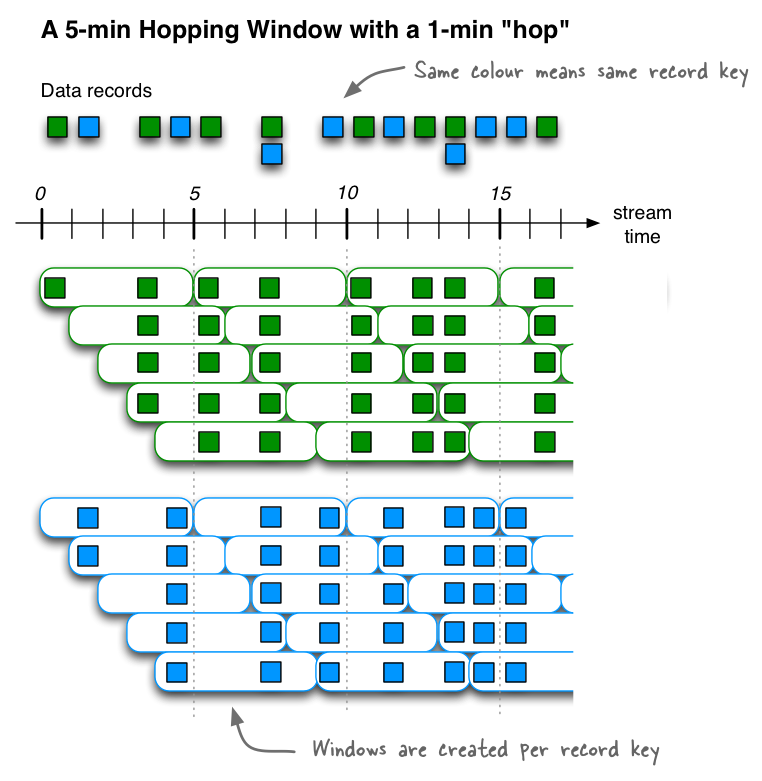
(2)Sliding Windows
是可能存在重叠的,即滑动窗口。
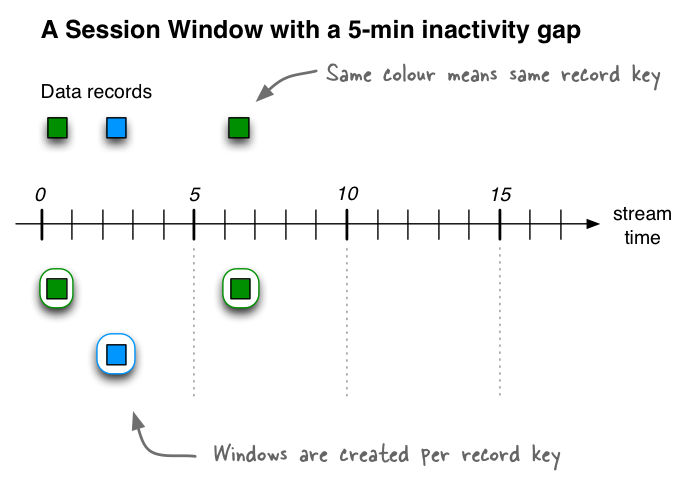
(3)session window
以上两种都是基于时间的,固定的窗口,还存在一种window: session window
当我们需要分析用户的一段交互的行为事件时,通常的想法是将用户的事件流按照“session”来分组。session 是指一段持续活跃的期间,由活跃间隙分隔开。通俗一点说,消息之间的间隔小于超时阈值(sessionGap),如果两个元素的时间戳间隔小于 session gap,则会在同一个session中。如果两个元素之间的间隔大于session gap,且没有元素能够填补上这个gap,那么它们会被放到不同的session中。
通过以上不同类别的基本指标和术语的了解,可以大体了解metric领域的一些知识,为以后的metric工作的进展做铺垫。
参考文献:
https://baike.baidu.com/item/%E4%B8%AD%E4%BD%8D%E6%95%B0
https://www.jianshu.com/p/68ab40c7f347
https://yq.aliyun.com/articles/64818
https://kafka.apache.org/11/documentation/streams/developer-guide/dsl-api.html#windowing
https://prometheus.io/docs/concepts/metric_types/
https://www.app-metrics.io/getting-started/metric-types/
http://www.cnblogs.com/nexiyi/p/metrics_sample_1.html