netty提供了三种方式和写相关:
(1) write(msg) ⇒ pass through pipeline
(2) flush()=> gathering write of previous written msgs
(3) writeAndFlush()=>short-cut for write(msg) and flush()
通过前文的分析可知,写并没有真正的去发送给远端,而是缓存起来。而flush可以理解为开始写。所以在实际使用netty(包括netty的案例)时,都很简单的使用了writeAndFlush(),简单明了。
所以服务器在发送数据时,则面对这样的情况:
write 1-> flush 1
write 2-> flush 2
write 3-> flush 3
netty作者提及作为最佳实践应该“Limit flushes as much as possible as syscalls are quite expensive.”
所以优化需要做的目标是:
write 1-> queue
write 2-> queue -> flush
write 3-> queue
翻阅cassandra的实现:
org.apache.cassandra.transport.Message.Dispatcher.Flusher
基本步骤如下:
(1)当需要写入数据时,查询map,获取writer, 没有则创建:map以nio event loop为key,这样避免每个socket就对应一个queue.
EventLoop loop = item.ctx.channel().eventLoop();
Flusher flusher = flusherLookup.get(loop);
if (flusher == null)
{
Flusher alt = flusherLookup.putIfAbsent(loop, flusher = new Flusher(loop));
if (alt != null)
flusher = alt;
}
flusher.queued.add(item);
flusher.start();
(2)将数据存入writer中的queue.
(3) writer定期去轮询queue中的数据,满足3个情况时,则都会flush,而多次无数据被轮询到时则关闭轮询以节约CPU资源
flush的三种情况:
(1) there have been three batches appear together (each could be singleton items, with arbitrary temporal separation)
(2) there has been one batch followed by a >10us pause
(2) there are more than fifty messages waiting
boolean doneWork = false;
FlushItem flush;
while ( null != (flush = queued.poll()) )
{
channels.add(flush.ctx);
flush.ctx.write(flush.response, flush.ctx.voidPromise());
flushed.add(flush);
doneWork = true;
}
runsSinceFlush++;
if (!doneWork || runsSinceFlush > 2 || flushed.size() > 50)
{
for (ChannelHandlerContext channel : channels)
channel.flush();
for (FlushItem item : flushed)
item.sourceFrame.release();
channels.clear();
flushed.clear();
runsSinceFlush = 0;
}
if (doneWork)
{
runsWithNoWork = 0;
}
else
{
// either reschedule or cancel
if (++runsWithNoWork > 5)
{
running.set(false);
if (queued.isEmpty() || !running.compareAndSet(false, true))
return;
}
}
eventLoop.schedule(this, 10000, TimeUnit.NANOSECONDS);
画一张图描述即为:
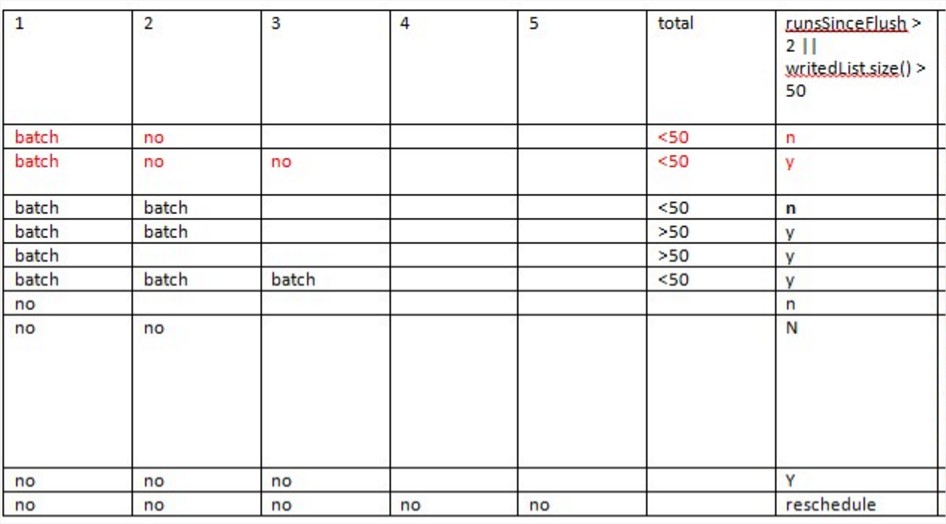
针对这种实现的条件控制:
if (!doneWork || runsSinceFlush > 2 || flushed.size() > 50)
给cassandra提过一个建议:移除!donework条件,因为只会延长一次loop周期(存在数据后第二次无数据),减少一次无意义的loop(2次无数据时),代码也清晰不少。因为用donework来翻转来实现“there has been one batch followed by a >10us pause”实在难看。cassandra给的回复是:
It is not >10us vs >20us; it is n ~>= 10us, and choosing between n and 2n; on some systems under high load n could be significantly greater than 10us, perhaps 100us, perhaps 1ms; making it twice n is potentially worse than just adding 10us.
In general, this code is pretty critical to the behaviour of the system. The current behaviour was chosen somewhat arbitrarily by me, but it has been fairly thoroughly tested. With sufficient testing a different arbitrary behavior would be fine
所以cassandra肯定充分测试了这些控制的合理性,例如10us的控制,5次无数据停掉loop,存在一笔数据延长一次loop而不是二次loop来发送。
总结:作为最佳实践,笔者果断引入,但是实测虽然有提高,但是不明显(例如低TPS可能提升不明显),可能必须在某种测试case下才大幅提升。不管如何,不需要穷举去证明它有了质的飞跃,只能说它是最佳实践,必然有其优势。