Cassandra主要通过node之间的数据同步复制来保持数据一致性,即使可以依靠事后的 repair和读修复等措施来修复,但是毕竟属于修复工作,而且也不见得“启用”: 例如auto repair默认纯属手工触发;读修复存在的一定的几率,例如默认0.1。所以保持一致性的核心方法仍然是数据同步复制。复制的性能直接影响了使用感受,当我们部署一批Cassandra node,建立一定复制策略的keyspace之后,我们开始关心对keyspace的每次操作究竟需要多久才能漫延到全网(全部备份node)。
前提知识:
在监控之前需要了解一些最基本的前提知识:
1 要不要复制
复制策略直接影响了我们需要考量的node数目,例如假设我们设置复制策略为SimpleStrategy ,且replication_factor=1,那么并没有复制的情况, 所以复制无从谈起。
示例: create keyspace Keyspace1 with replication_factor = 1and placement_strategy = 'org.apache.cassandra.locator.SimpleStrategy';
2 复制到哪些node
从(1)可以看出,不需要复制等于放弃了cassandra的优秀功能:允许node单点故障。所以肯定会配置成复制,那么对于一个数据操作,会复制到哪些node?根据复制策略可分为两类:
2.1 SimpleStrategy ,replication_factor=N, 对于某个数据操作,会根据数据的partition key决定放置的node,同时将数据存储在此node之后N-1的node以形成N份数据,参考下文:
示例:ksnorep | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
“places the first replica on a determined by the partitioner. Additional replicas are placed on the next s clockwise in the ring without considering topology (rack or data center location).”
2.2 NetworkTopologyStrategy,这种策略主要针对 multiple data centers,且存在机柜rack的概念,假设配置成DC1:2,DC2:3,DC3:4,一份数据会被存储成2+3+4=9份,而对于每个DC怎么存储,可以参考下文(区别于SimpleStrategy,该种策略会尽量将数据分布在同一DC的不同机柜之上,从而提供最高的可靠性保障)。
示例: system_traces | True | org.apache.cassandra.locator.NetworkTopologyStrategy | {"DC2":"3","DC1":"3","DC4":"3","DC3":"3"}
“NetworkTopologyStrategy places replicas in the same data center by walking the ring clockwise until reaching the first in another rack.NetworkTopologyStrategy attempts to place replicas on distinct racks because s in the same rack (or similar physical grouping) often fail at the same time due to power, cooling, or network issues.”
了解最基本的知识后,我们就会避免脱离基于某个具体keyspace的复制策略来谈复制的性能,同时即使将复制延时的考虑限制在某一个keyspace中,我们也能意识到,我们的每笔数据操作复制到的node也不定相同,虽然总数是相同的。
复制原理
在具备上面的最基本的知识后,我们开始来设计监控复制延时的方法,此时我们应该带着问题回到原点,数据同步复制是如何实现的?我们监控的应该是什么?
Cassandra的数据同步复制实现:Driver首先会根据一定的策略(Driver的policy配置)将写操作发送到协调者(“coordinator”),然后协调者根据复制策略和分区找出需要存储数据的一批节点,将写操作发到所有的备份节点,发完之后,等待callback,而对于call back的等待时间完全根据写操作的一致性级别来决定,例如一致性级别为ONE, 那么只要有一个callback返回,立马通知客户端该写操作完成。可见说是复制,其实是所有node的写操作一起触发。
org.apache.cassandra.service.StorageProxy.performWrite(IMutation, ConsistencyLevel, String, WritePerformer, Runnable, WriteType)
public static AbstractWriteResponseHandler performWrite(IMutation mutation,
ConsistencyLevel consistency_level,
String localDataCenter,
WritePerformer performer,
Runnable callback,
WriteType writeType)
throws UnavailableException, OverloadedException
{
String keyspaceName = mutation.getKeyspaceName();
AbstractReplicationStrategy rs = Keyspace.open(keyspaceName).getReplicationStrategy();
Token tk = StorageService.getPartitioner().getToken(mutation.key());
List<InetAddress> naturalEndpoints = StorageService.instance.getNaturalEndpoints(keyspaceName, tk); //计算replicate nodes
Collection<InetAddress> pendingEndpoints = StorageService.instance.getTokenMetadata().pendingEndpointsFor(tk, keyspaceName);
AbstractWriteResponseHandler responseHandler = rs.getWriteResponseHandler(naturalEndpoints, pendingEndpoints, consistency_level, callback, writeType);
// exit early if we can't fulfill the CL at this time
responseHandler.assureSufficientLiveNodes();
performer.apply(mutation, Iterables.concat(naturalEndpoints, pendingEndpoints), responseHandler, localDataCenter, consistency_level);
return responseHandler;
}
response block的数目:
public int blockFor(Keyspace keyspace)
{
switch (this)
{
case ONE:
case LOCAL_ONE:
return 1;
case ANY:
return 1;
case TWO:
return 2;
case THREE:
return 3;
case QUORUM:
case SERIAL:
return quorumFor(keyspace);
case ALL:
return keyspace.getReplicationStrategy().getReplicationFactor();
case LOCAL_QUORUM:
case LOCAL_SERIAL:
return localQuorumFor(keyspace, DatabaseDescriptor.getLocalDataCenter());
case EACH_QUORUM:
if (keyspace.getReplicationStrategy() instanceof NetworkTopologyStrategy)
{
NetworkTopologyStrategy strategy = (NetworkTopologyStrategy) keyspace.getReplicationStrategy();
int n = 0;
for (String dc : strategy.getDatacenters())
n += localQuorumFor(keyspace, dc);
return n;
}
else
{
return quorumFor(keyspace);
}
default:
throw new UnsupportedOperationException("Invalid consistency level: " + toString());
}
}
通过对数据同步复制实现的理解,可知想要监控的复制延时,不仅和复制策略有关,与读写一致性级别的设置也是息息相关的,从常规理解来看,我们想要监控的是Cassandra“写完一个node”到写完所有备份节点的时间差,但是实际上,我们想要监控的是“写操作完成”到写完所有备份节点之间的时间差。
所以脱离写一致性谈复制延时也是脱离实际的。
经过以上分析,我们可以明确了我们的目标:针对某keyspace,基于它的复制策略和客户端写的一致性级别我们想知道一个写操作完成到所有备份node都完成数据操作之间的时间差。
监控复制延时方案选型和设计
了解以上基本知识,我们开始去设计监控复制延时:
方案1:写,读,时间差
1. 客户端1写一条新操作(与业务实际的写一致性级别相同),记录完成时间t1;
2. 客户端2读数据,要求读到所有备份节点,且所有node都存在这条记录时记录时间
3. 计算时间差t2-t1=延时。
实际操作,会将步骤2移动到步骤1之前,以避免误差。此时问题呈现:如何实现步骤2:判断所有备份节点是否存在新数据,此时我们大体构思两种思路:
2.1. 利用Cassandra driver去读实现,一致性级别设置成与业务一致的级别,例如local_quorum, 这样并不能反映所有node状况,它最多能保证3个node中读到的2个node的数据存在一个是最新数据,而一致性级别设置成all? 不能解决,因为假设一个node没有数据,不会影响整体结果的判断;
2.2 查询cassandra的log: 对于同步数据的请求会有fwd关键字,但是试想,这种针对某个数据操作的日志会写在非debug日志么。
同时步骤2还需要确定是每次的写入到底会复制到哪些node,因为不同数据的partition key可能不同导致存在的备份node不尽相同(虽然总数相同)。
举一个简单的例子,对于复制因子是1的简单复制策略(replication_factor = 1,’org.apache.cassandra.locator.SimpleStrategy’),插入不同的数据,数据存在不同的node:
cqlsh:keyspace1> INSERT INTO table1(id) VALUES(8); Tracing session: 646e0e20-de58-11e4-a1cd-ad60cc57d404 activity | timestamp | source | source_elapsed -------------------------------------------------------------------------------------------------+----------------------------+----------------+---------------- Appending to commitlog [SharedPool-Worker-1] | 2015-04-09 01:30:34.196000 | 10.194.250.156 | 2233 Adding to table1 memtable [SharedPool-Worker-1] | 2015-04-09 01:30:34.196000 | 10.194.250.156 | 2272 cqlsh:keyspace1> INSERT INTO table1(id) VALUES(9); Tracing session: 6a00e790-de58-11e4-a1cd-ad60cc57d404 activity | timestamp | source | source_elapsed -------------------------------------------------------------------------------------------------+----------------------------+---------------+---------------- Appending to commitlog [SharedPool-Worker-1] | 2015-04-09 01:33:29.917000 | 10.89.108.188 | 640 Adding to table1 memtable [SharedPool-Worker-1] | 2015-04-09 01:33:29.917000 | 10.89.108.188 | 734
同样对于NetworkTopologyStrategy也面临同样的问题。所以这种方法的另外一个难处在于自己计算存储在哪些node上,假设真的很容易计算出(可以通过driver中clusterMetadata.getReplicas(Metadata.quote(keyspace), partitionKey),代码实例一,或者使用nodetool执行nodetool getendpoints keyspace table 34565678),这个时候要保证自己的读确实能反映当前node的情况,可能想到的方法是设置一致性级别是LOCAL_ONE,然后让每次请求发送到协调者上,即使可以做到也不行,因为经测试在备份节点上执行一致性级别是LOCAL_ONE的可能返回的是其他Node结果,翻看代码(代码实例二):
在LOCAL_ONE级别时,假设不read repair时,将只发一个数据请求,且是本node(因为之前的targetReplicas已经过排序将本机放在第一位);但是实际实际情况是存在0.1概率的read repair,,会发2个DataRequests到更多的node。
示例一:
Metadata metadata = cluster.getMetadata();
TableMetadata table = metadata.getKeyspace("keyspace").getTable("table");
Insert value = QueryBuilder.insertInto(table).value("id", "1232");
Set<Host> replicas = metadata.getReplicas(Metadata.quote(value.getKeyspace()), value.getRoutingKey());
示例二:
makeDataRequests(initialReplicas.subList(0, 2)); if (initialReplicas.size() > 2) makeDigestRequests(initialReplicas.subList(2, initialReplicas.size()));
在等待结果时,不见得是本结点先返回(程序是先发远程异步请求,再处理本地);
public void response(MessageIn<TMessage> message)
{
resolver.preprocess(message);
int n = waitingFor(message)
? recievedUpdater.incrementAndGet(this)
: received;
if (n >= blockfor && resolver.isDataPresent())
{
condition.signalAll();
// kick off a background digest comparison if this is a result that (may have) arrived after
// the original resolve that get() kicks off as soon as the condition is signaled
if (blockfor < endpoints.size() && n == endpoints.size())
StageManager.getStage(Stage.READ_REPAIR).execute(new AsyncRepairRunner());
}
}
仔细阅读代码,不考虑重试和动态snitch,理想情况下是这样的(基于场景:假设存在3个DC, 且本地DC存在5个Node,其中本地复制因子是3:假设协调者是当前Node):
| 一致性级别\类别 | Target Replicated | Request | Request Complete |
| ONE(不修复) | Current node | 一个Data Request | Data Request返回 |
| ONE(修复) | Local DC node(假设总数不够一致性级别,再另外添加其他DC Node) | 当Target大于一致性级别要求(此地为1)时,发2个Data Request,其他Digest Request. | 收到一个返回,假设不是Data Request返回,继续等待,假设是,结束等待,返回第一个Data Request返回的Data。 |
| LOCAL_ONE(不修复) | 同ONE(不修复) | ||
| LOCAL_ONE(修复) | 同ONE(修复) | 要求收到LOCAL DC Node的Data Request才返回,但是结果不一定是哪个Data Request的结果,以先到为准. | |
| TWO(不修复) | Two Node | 一个Data Request,一个Digest Request | 2个请求返回都收到。获取结果时,比较Digest,如果不一致。修复这2个Node |
| TWO(修复) | 同ONE(修复) | 至少2个请求返回,且有Data Request返回。获取结果时,比较Digest,如果不一致,修复Target Replicated Node | |
可见LOCAL_ONE可能真实反映当前Node情况,之所以说是可能,是因为还存在两种例外情况:(1)当发现2.5S还没有接受到返回时,会尝试发新的请求到另外一个Node【org.apache.cassandra.service.AbstractReadExecutor.SpeculatingReadExecutor.maybeTryAdditionalReplicas()】,(2)snitch方法默认都被包装在dynamic snitch这个adapter里面,它会衡量哪个结点速度最快然后提供路由信息,所以会对已经排序的结果(本结点第一位)进行调整。
private static IEndpointSnitch createEndpointSnitch(String snitchClassName) throws ConfigurationException
{
if (!snitchClassName.contains("."))
snitchClassName = "org.apache.cassandra.locator." + snitchClassName;
IEndpointSnitch snitch = FBUtilities.construct(snitchClassName, "snitch");
return conf.dynamic_snitch ? new DynamicEndpointSnitch(snitch) : snitch;
}
同时实际测试也表现大多能返回本地node结果,但是仍然存在一定的概率反映的是本地其他Node。
所以基于以上分析,一般性的三部曲: 写,读,计算时间差难搞定,因为存在3个因素(1)table读修复概率为默认为0.1;(2) driver每次发送到的结点不见得就是要查询的结点,需要控制;(3)动态snitch可能会查询结点的优先级。
由于第一点一般不会如此做,所以放弃这种方案,尝试其他方案。
PS: 读写差异:
//write List<InetAddress> naturalEndpoints = StorageService.<strong><em>instance</em></strong>.getNaturalEndpoints(keyspaceName, tk); //get endpoints by replicationStrategy //read List<InetAddress> liveEndpoints = StorageService.<strong><em>instance</em></strong>.getLiveNaturalEndpoints(keyspace, pos); DatabaseDescriptor.<em>getEndpointSnitch</em>().sortByProximity(FBUtilities.<em>getBroadcastAddress</em>(), liveEndpoints); //sort by endpoint snitch
方案2: 写一致性级别ALL
此时只能另辟蹊径,考虑到写一致性级别是ALL时,要求所有的node都复制完成才能返回结果给客户端,所以很明显,所以如果把测试的数据设置成一致性级别all,耗费的时间就是:网络延时+复制node处理时间。
这种方式一定程度反映了复制的延时,至少能保证:复制延时一定在计算出的时间内。
但是之所以说一定程度,是因为耗费的时间本身多包含了call back通知协调者的网络延时,在网络延时占居主要因素时,这种方式算出的时间并不能真实反映复制延时,因为复制完成的界定并不应该包含callback的过程(虽然callback是一个很简洁的消息体)。
举例说明网络延时的重要性:对于以下2笔插入操作,分别存储在node 10.89.108.188( 不同的网段)和10.224.57.168(相同网段),经过分析可知差异主要体现在网络延时,例如对于前者:从开始复制到复制完成之后接受到callback耗费了402-3=399(ms),而node实际处理复制操作大概在0.4ms,而前者耗费为3.7-0.5=2.8(ms),实际处理消耗2.4ms,可见相差了390+毫秒。
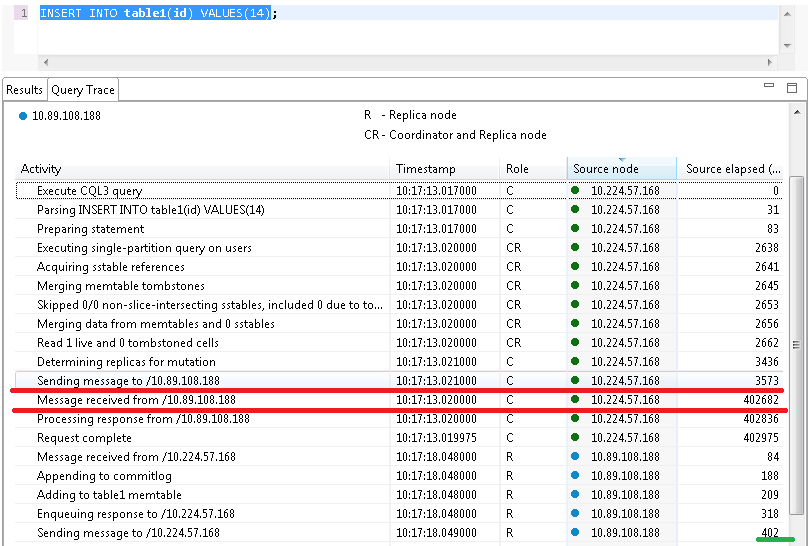
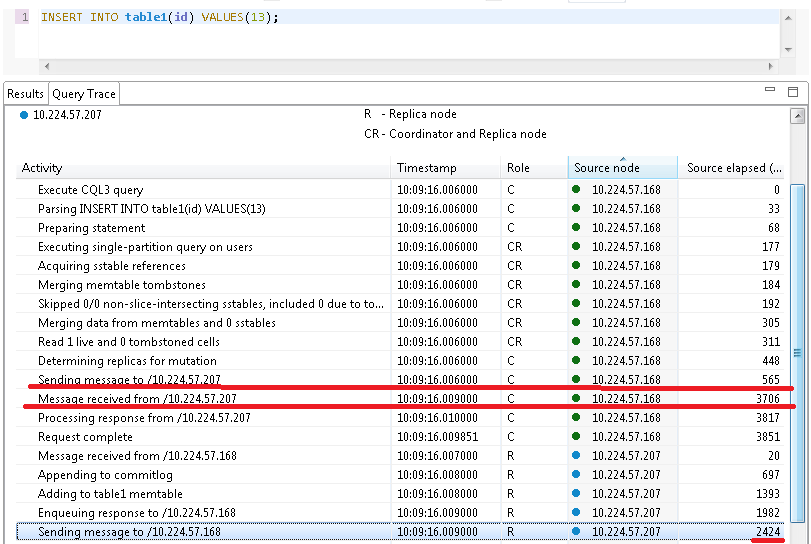
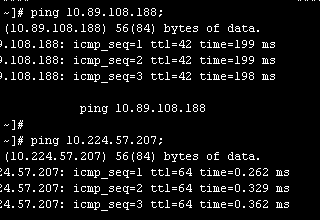
此时我们直接ping下这2个ip: 可见两者网络延时之大。相差将近200ms,也从侧面说明了一些情况下网络延时占居了差异的主要原因,此时需要减去callback的网路延时才能准确评估复制延时。
这种监控方式也存在另外一个小问题:同时设置一致性级别为all时,假设所有复制的node中有一个down的情况,写操作会抛出异常,提示:备份要求的数目大于alive的node数目,当然这不影响,因为不可能一直都是down.
方案3: Tracing
假设基于以上的方案不能非常准确的完成监控,是否可以利用上述分析用到的分析方法(打开tracing),因为tracing的信息非常详细,可以找出大致的网络延时,首先了解下实现方法:
例如:
Cluster build = Cluster.builder().addContactPoint("10.224.57.168").withAuthProvider(new PlainTextAuthProvider("fujian","pass")).build();
Session connect = build.connect("test_keyspace1");
Statement statement=QueryBuilder.insertInto("test_table1").value("id", 1213211).value("age", 111111).enableTracing();
List<Event> events = execute.getExecutionInfo().getQueryTrace().getEvents();
这种方法能计算耗费时间,但是存在的两个问题:
(1) 等于让server在处理时,加上了tracing的处理(tracing会写system_traces.events和system_traces.session表),虽然核心处理都是异步操作,但是多少会影响复制延时的衡量。
public static void trace(final ByteBuffer sessionIdBytes, final String message, final int elapsed)
{
final String threadName = Thread.currentThread().getName();
StageManager.getStage(Stage.TRACING).execute(new WrappedRunnable() //异步方式
{
public void runMayThrow()
{
Mutation mutation = new Mutation(Tracing.TRACE_KS, sessionIdBytes);
ColumnFamily cells = mutation.addOrGet(CFMetaData.TraceEventsCf);
CFRowAdder adder = new CFRowAdder(cells, cells.metadata().comparator.make(UUIDGen.getTimeUUID()), FBUtilities.timestampMicros());
adder.add("activity", message);
adder.add("source", FBUtilities.getBroadcastAddress());
if (elapsed >= 0)
adder.add("source_elapsed", elapsed);
adder.add("thread", threadName);
Tracing.mutateWithCatch(mutation);
}
});
}
(2) 一致性级别设成非ALL情况(例如ONE),得出的时间消耗并不包含所有node的复制,因为记录的tracing是以请求处理结束为止,而不是所有node复制完成为止。
所以基于以上分析取长补短得出方案4:
方案4: 方案2+方案3
经过以上分析,可以得出最终方案4::结合一致性级别All+Tracing:参考方案3的Code sample.
Cluster build = Cluster.builder().addContactPoint("10.224.57.168").withAuthProvider(new PlainTextAuthProvider("fujian","pass")).build();
Session connect = build.connect("test_keyspace1");
Statement statement=QueryBuilder.insertInto("test_table1").value("id", 1213211).value("age", 111111).setConsistencyLevel(ConsistencyLevel.ALL).enableTracing();
long time=System.nanoTime();
ResultSet execute = connect.execute(statement);
System.out.println((System.nanoTime()-time)/1000/1000); //计算耗时,包含callback时间
List<Event> events = execute.getExecutionInfo().getQueryTrace().getEvents(); //如果上述复制延时较大,可以分析EVENTS减去网络延时。
System.out.println(execute.getExecutionInfo().getQueryTrace().getDurationMicros()); //从协调者角度完成请求耗时,不是从客户端角度。
综上,很难找出一个非常准确的方法来衡量复制的延时,能思考出的比较理想的方式是:插入一条一致性级别为all的数据,且打开tracing,此时,我们一方面能直接用消耗的时间大体反映复制延时,同时如果要非常准确(可以减去网络延时/2)或者大体分析出延时较长的原因,可以拿出event list来分析。当然这里的忽略的因素是tracing对执行的影响,个人认为影响还是很小的。
但是实践中发现,这个方案仍然存在问题,因为假设利用写一致性级别来衡量,就会受制于一个参数:write_request_timeout_in_ms,而这个参数默认是2s, 即一个请求在2S之内完成不了就会抛出异常结束,而客户端直接抛出异常。从这个角度来看,超过2S的复制延时具体是多长时间我们无法获悉。
# How long the coordinator should wait for writes to complete
write_request_timeout_in_ms: 2000
Tracing.trace("Write timeout; received {} of {} required replies", ex.received, ex.blockFor);
cqlsh> INSERT INTO table1(site,id) VALUES(1222,1222);
code=1100 [Coordinator node timed out waiting for replica nodes' responses] message="Operation timed out - received only 7 responses." info={'received_responses': 7, 'required_responses': 8, 'write_type': 0, 'consistency': 7}
Statement trace did not complete within 10 seconds
总结: 经过4种方案的选择和分析,我们难以搞定得出复制延时的需求,但是在部署完所有node后,我们可以通过方案4来大致锁定没有业务请求时复制延时是多大,有没有超过2S,假设延时超过预期,还得具体分析根本原因(从实际方案的方案选型中,网络延时和node处理耗时是延时的重要要素),但是换一个角度来说,如果将可容忍的复制延时定义为2s,那么这种方案已经满足我们的需求,因为至少已经反映是否超过2s,在实际操作中,不防将Replication factor设置成全网复制,然后测试是否在2S内,如果没有业务时,超过2S,那网络本身就不太理想。如果排除网络因素,还是耗时较长,可以从node实际处理来分析了,此时实际上已从replicated问题转化为本地node写的问题了。
PS: 方案4的一些有用信息:
Exception in thread “main” com.datastax.driver.core.exceptions.UnavailableException: Not enough replica available for query at consistency ALL (11 required but only 10 alive)
可以表明,有1结点服务不正常,查询后果然如此:
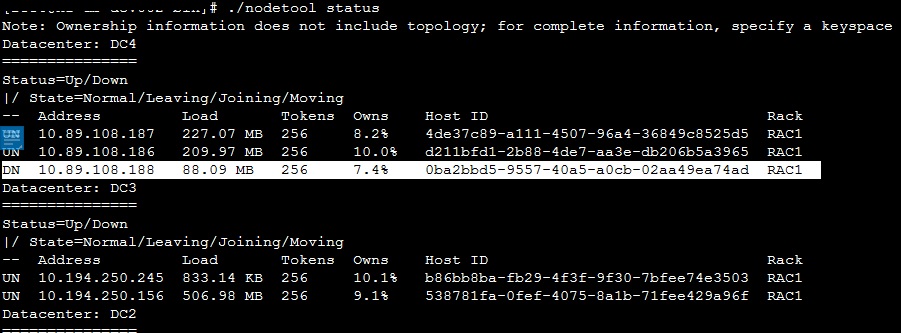
启动down的结点后,重新执行获取延时416ms(自己测试环境).
然后如果2S之内没有返回,会报出有多少结点没有完成replicate.
Coordinator node timed out waiting for replica nodes’ responses] message=Operation timed out – received only 7 responses info={‘received_responses’: 7, ‘required_responses’: 8, ‘write_type’: 0, ‘consistency’: 7
可以表明有1个结点在2S之内还没有完成复制。
另外,对于网络延时,分布在最远的2个国家最理想的网络延时是多少?赤道/光速是133毫秒,所以单程在66ms左右。从这个角度看,最远2个DC的复制延时至少>66ms.排除网络延时本身,剩下的时间就是NODE的处理时间。
网络延时大的情求trace, 注意不同节点使用自己的时间计算。而不是累加。
附:
50d5ef70-2dad-11e8-b04a-db99880ac283 50e30ed0-2dad-11e8-b222-7b3aa6a73e7b READ message received from /10.252.8.28 10.254.205.33 16 MessagingService-Incoming-/10.252.8.28 //这个时间是相对10.254.205.33的。 50d5ef70-2dad-11e8-b04a-db99880ac283 50fcb150-2dad-11e8-b222-7b3aa6a73e7b Executing single-partition query on wbxpcnaccount 10.254.205.33 94 SharedPool-Worker-2 50d5ef70-2dad-11e8-b04a-db99880ac283 511653d0-2dad-11e8-b222-7b3aa6a73e7b Acquiring sstable references 10.254.205.33 100 SharedPool-Worker-2 50d5ef70-2dad-11e8-b04a-db99880ac283 512ff650-2dad-11e8-b222-7b3aa6a73e7b Merging memtable tombstones 10.254.205.33 107 SharedPool-Worker-2 50d5ef70-2dad-11e8-b04a-db99880ac283 514998d0-2dad-11e8-b222-7b3aa6a73e7b Key cache hit for sstable 84299 10.254.205.33 123 SharedPool-Worker-2 50d5ef70-2dad-11e8-b04a-db99880ac283 51633b50-2dad-11e8-b222-7b3aa6a73e7b Seeking to partition beginning in data file 10.254.205.33 125 SharedPool-Worker-2 50d5ef70-2dad-11e8-b04a-db99880ac283 517d04e0-2dad-11e8-b222-7b3aa6a73e7b Skipped 0/1 non-slice-intersecting sstables, included 0 due to tombstones 10.254.205.33 247 SharedPool-Worker-2 50d5ef70-2dad-11e8-b04a-db99880ac283 5196a760-2dad-11e8-b222-7b3aa6a73e7b Merging data from memtables and 1 sstables 10.254.205.33 252 SharedPool-Worker-2 50d5ef70-2dad-11e8-b04a-db99880ac283 51b049e0-2dad-11e8-b222-7b3aa6a73e7b Read 2 live and 0 tombstone cells 10.254.205.33 273 SharedPool-Worker-2 50d5ef70-2dad-11e8-b04a-db99880ac283 51c9ec60-2dad-11e8-b222-7b3aa6a73e7b Enqueuing response to /10.252.8.28 10.254.205.33 313 SharedPool-Worker-2 50d5ef70-2dad-11e8-b04a-db99880ac283 51e38ee0-2dad-11e8-b222-7b3aa6a73e7b Sending REQUEST_RESPONSE message to /10.252.8.28 10.254.205.33 368 MessagingService-Outgoing-/10.252.8.28 50d5ef70-2dad-11e8-b04a-db99880ac283 50d971e5-2dad-11e8-b04a-db99880ac283 reading digest from /10.254.205.33 10.252.8.28 1115 SharedPool-Worker-4 50d5ef70-2dad-11e8-b04a-db99880ac283 50d998f4-2dad-11e8-b04a-db99880ac283 Sending READ message to /10.254.205.33 10.252.8.28 1142 MessagingService-Outgoing-/10.254.205.33 50d5ef70-2dad-11e8-b04a-db99880ac283 51087121-2dad-11e8-b04a-db99880ac283 REQUEST_RESPONSE message received from /10.254.205.33 10.252.8.28 330202 MessagingService-Incoming-/10.254.205.33
网络延时小的。
50d5ef70-2dad-11e8-b04a-db99880ac283 50d74f06-2dad-11e8-b04a-db99880ac283 reading digest from /10.252.8.50 10.252.8.28 558 SharedPool-Worker-4 50d5ef70-2dad-11e8-b04a-db99880ac283 50d79d20-2dad-11e8-b04a-db99880ac283 Sending READ message to /10.252.8.50 10.252.8.28 582 MessagingService-Outgoing-/10.252.8.50 50d5ef70-2dad-11e8-b04a-db99880ac283 50d9c005-2dad-11e8-b04a-db99880ac283 REQUEST_RESPONSE message received from /10.252.8.50 10.252.8.28 1384 MessagingService-Incoming-/10.252.8.50